今回は「Internet Explorer」や「Google Chrome」などのブラウザでインターネットでWebサイトを閲覧した時の仕組みについて解説します。

インターネットでは様々な機器(ノード)がネットワーク経路に存在しています。
- ファイアウォール
- ロードバランサ―
- ルーター
- スイッチ
- サーバ
- NAS(Network Attached Storage)
- UPS(無停電電源装置)
ただこれだけの多数・多種類のノードがネットワーク経路に存在していると、障害が発生して突然ネットワークがつながらなくなることがあります。
(本当はそんなことがあってはいけませんが、絶対に壊れないということがありえません)
よく聞く障害は「インターネットにつながらなくなった」「メールが送信できなくなった」などです。
業務で一番よく使うので、一番気が付きやすいです。
今回は Google Chrome や Internet Expolorer(IE)などのブラウザでWebサイトを閲覧する仕組みを勉強することで、インターネットが閲覧できない等の現象が発生した場合に、ネットワーク全体でどこに問題があるのか調べられるようになると思います。
目次
Webサイトを閲覧する時、内部ではどうなっているのか?
ブラウザで「Yahoo!」や「Google」を閲覧する、その場合、内部では何が起きているのでしょうか?
ちなみに私は「Google Chrome」を利用しています。
その理由ですが、ベンチマークテストをやると分かりますが、他のブラウザに比べてレスポンスがけた違いに速いです。
もちろんIEなど他のブラウザも細かい設定をすれば(レジストリをいじる等)、Webサイトを閲覧した時のレスポンスが速くなると思います。
しかし「ブラウザを細かく設定をしなければいけない」時点でGoogle Chromeに軍配が上がると思います。
なぜなら、単純にインストールしてサクサクとインターネットにアクセスできる、これが最高です。
余計なことをする必要がなくてベストの状態で入手できてすぐ使えます。
話が変わりますが、クラウド環境のAWSのサービスもそうです。
アカウントを登録して、その数分後にEC2インスタンスを作り、数分後にはEC2インスタンスにログインしてコマンドが実行できます。
このサービスの即時性というか、すぐに使えるというサービスは想像以上にすごいことだと思います。
「ブラウザでWebサイトを閲覧する」 ということはどういうことか
じゃっかん話は飛びましたが、「ブラウザでWebサイトを閲覧する」 ということはどういうことなのでしょうか。
手順を追って説明してみます。
1.ブラウザを起動しアドレス欄にURLを入力する
まずは「Google Chrome」を起動し、URLに「http://yahoo.co.jp」を入力してEnterキーを押下してみます。
※IT業界では「押下(おうか)」という用語を使います。
押下とはキーボードを押すことです。
2.ブラウザがURLを分解する
URLを指定されたブラウザは、URLを分解して解析します。
以下の3つの要素で解析します。
- プロトコル
- ホスト名
- リソース名
Tomcatとか使っていると、更に8080などの「ポート番号」の指定も入ってきます。
【例】
http://example.co.jp:8080 ← この8080がポート番号です。
例えば、「https://news.yahoo.co.jp/flash(Yahoo!ニュースの速報)」のURLを詳しく見ると
プロトコル:https
ホスト名:news.yahoo.co.jp
リソース:flash
と分解できます。
※プロトコルとはネットワークの通信規約を意味する用語です。
「通信規約」とは、例えばスパイ同士が「山」と言ったら「川」と答えて、お互いを本物と判断して情報を交換するといったような「規則」のことです。
もしここで「山」と言ったら「海」と返ってきたら偽物のスパイなので情報は交換できません。
辞書を見ると、プロトコルとは「外交儀礼」という説明もあります。
呼び方もプロトコルとか、プロトコールなどと言います。
3.URLのホスト名からIPアドレスを調べる
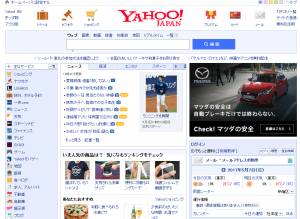
たとえば、ブラウザで「www.yahoo.co.jp」というホストにアクセスして「Yahoo!」のサイトを閲覧するとします。
さらに言うと、Yahoo!ニュースを閲覧したいとします。
その場合は、ブラウザが Yahoo! のホスト(www.yahoo.co.jp)に対してニュースのリソースを要求しています。
「www.yahoo.co.jp」は「ホスト名」で、人間がわかりやすいように付けられた名前です。
ブラウザはインターネット上で目的のコンピュータを見つけようとしますが、内部的には「ホスト名」ではなく「IPアドレス」で探しています。
どうやって「IPアドレス」を調べるのか?
ブラウザは DNS (Domain Name System)というプロトコルを使ってIPアドレスを調べます。
例えば「www.yahoo.co.jp」もちゃんとIPアドレスを持っています。
|
$ nslookup www.yahoo.co.jp Non-authoritative answer: ←「answer」の部分をチェックする |
上記は「nslookup」コマンドで www.yahoo.co.jp のIPアドレスを調べた結果です。
もっと分かりやすいコマンド結果が返ってるかと思いましたが、意に反して分かりにくい結果が返ってきました(笑)
詳しく解説すると、チェックする部分は「answer」の部分です。
この「answer」の部分に実際にwww.yahoo.co.jpが持っているIPアドレスが表示されます。
Address: 183.79.248.252
このようにインターネット上に存在するコンピュータは、みんな「ホスト名」と「IPアドレス」を持っています。
DNSのシステムでホスト名からIPアドレスを調べて、IPアドレスの情報を取得します。
4.パソコンのブラウザが、Webサーバの80番ポートにリクエストを送る
パソコンのブラウザが
- HTTPプロトコルで
- Webサーバ(www.yahoo.co.jp)の
- 80番ポートに
HTTPリクエストを送ります。
なぜ80番ポートなのでしょうか?
理由は、インターネットの「一般的な規則」で80番と決まっているからです。
あくまでも「一般的な規則」で法律で決まっているわけではないので、Webサーバは80番ポートを使わずに79番ポートを使っても良いです。
そこは自由です。
しかし79番ポートで待ち受けているサーバにアクセスするコンピュータはいませんし、いたとしてもネットワークの途中の経路で79番ポートはブロックされている確率が高いので結局は通信はできないと思います。
なぜなら一般的な規則から外れた通信は、ファイアウォールでブロックされる対象になります。
サーバーを構築するITエンジニアは、Webサーバー環境を構築しますが、一般的な規則を守る前提で設計や構築をします。
理由は、一般的な規則を元に設計・構築をした方がトラブルがないからです。
しかし組織によってはセキュリティを考慮して、社内サーバの10080番ポートへアクセスするように設定しているところもあったりします。
※要するにみんながポリシーを共有できてさえいれば「何でもいい」ですし、自由に設定しても問題ありません。
HTTPリクエストとは?
複雑な話になってきていますが、分かりやすく説明します。
ブラウザはサーバに対して「Yahoo!ニュースを見せてほしい等」の HTTPリクエストを送ります。
HTTPリクエストは以下のような形式です。
ちなみに以下は「生ログ」である。
| www.go-journey.club 124.xxx.xxx.xxx – – [07/May/2017:05:16:50 +0900] “GET /archives/1687 HTTP/1.1” 200 157055 “https://www.google.co.jp/” “Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.96 Safari/537.36” |
ここの「”GET /archives/1687 HTTP/1.1″」の部分がHTTP GETリクエストです。
“https://www.google.co.jp/”とログが残っているから、Google経由でアクセスが来たと思われます。
5.ブラウザがサーバからレスポンスを受け取る
このGETリクエストを受け取ったWebサーバーは以下のようなレスポンスを返します。
「HTTP/1.1″ 200」
「HTTP/1.1」は、HTTPプロトコルのバージョン1.1という意味です。
次世代のHTTP/2の解説は以下を参照

ちなみに以下はRFC2068のドキュメントの抜粋である。
| Fielding, et. al. Standards Track [Page 6]
RFC 2068 HTTP/1.1 January 1997 1 Introduction 1.1 Purpose The Hypertext Transfer Protocol (HTTP) is an application-level protocol for distributed, collaborative, hypermedia information systems. This specification defines the protocol referred to as “HTTP/1.1”. Practical information systems require more functionality than simple retrieval, including search, front-end update, and annotation. |
RFCを引用してみたが、やはり英文だと分かりにくいのでGoogle翻訳で翻訳します。
| RFC 2068 HTTP / 1.1 1997年1月
1はじめに 1.1目的 ハイパーテキスト転送プロトコル(HTTP)は、分散型、共同型、ハイパーメディア情報システム向けのアプリケーションレベルのプロトコルです。 この仕様は、 “HTTP / 1.1″と呼ばれるプロトコルを定義します。 実用的な情報システムでは、検索、フロントエンドの更新、アノテーションなど、単純な検索よりも多くの機能が必要です。 |
HTTP/1.1がドキュメント化されたのが1997年1月なので、2017年の今は20年経過しているということです。
かなり古いプロトコルですよね。
まだまだレンタルサーバー会社で対応しているところは少ないですが、今後は徐々にレンタルサーバーも HTTP/2 をサポートしていくことになるでしょう。
話が脱線しましたが、「HTTP/1.1」プロトコルでGETリクエストを受け取ったWebサーバーは、以下のようなレスポンスをブラウザに返します。
※参考にcurlコマンドを実行してログを表示させています。
| $ curl -i www.yahoo.co.jp HTTP/1.1 200 OK Server: ATS Date: Thu, 16 Mar 2017 14:05:30 GMT Content-Type: text/html; charset=UTF-8 P3P: policyref=”http://privacy.yahoo.co.jp/w3c/p3p_jp.xml”, CP=”CAO DSP COR CUR ADM DEV TAI PSA PSD IVAi IVDi CONi TELo OTPi OUR DELi SAMi OTRi UNRi PUBi IND PHY ONL UNI PUR FIN COM NAV INT DEM CNT STA POL HEA PRE GOV” X-Content-Type-Options: nosniff X-XSS-Protection: 1; mode=block X-Frame-Options: SAMEORIGIN Vary: Accept-Encoding Expires: -1 Pragma: no-cache Cache-Control: private, no-cache, no-store, must-revalidate X-XRDS-Location: https://open.login.yahooapis.jp/openid20/www.yahoo.co.jp/xrds X-Frame-Options: SAMEORIGIN Age: 0 Transfer-Encoding: chunked Connection: keep-alive Via: http/1.1 edge2078.img.djm.yahoo.co.jp (ApacheTrafficServer [c sSf ]) |
6.レスポンスをブラウザに表示する
サーバからのレスポンスを受け取ったブラウザは、ヘッダの最初の部分の「HTTP/1.1 200 OK」という数字でリクエストが成功したことを知ります。
なぜ200番なのかというと、HTTPでは「200番は通信の成功」と決めてあるからです。
ブラウザがレスポンスとして受け取ったHTMLをブラウザ上で表示します。
それをユーザーが閲覧します。
これが「ホームページを見る」ときの、大まかな流れです。
サーバのレスポンスには2種類ある「静的レスポンス」、「動的レスポンス」
レスポンスには2種類あります。
- 静的なレスポンス
- 動的なレスポンス
静的レスポンスとは?
静的なレスポンスの場合、Webサーバーはサーバー上に置かれた index.html などのHTMLファイルや xxx.jpg などの画像ファイルをインターネット経由で送ります。
(つまりブラウザがファイルを全部ダウンロードします)
Webサーバーのハードディスクに入っているファイルがインターネットを通じて、私たちのパソコンに転送されてきているのです。
「このサイトは重い」「この画像ファイルは大きいから表示に時間が掛かる」という会話を聞いたことがあるかもしれませんが、理由は「5MBもある画像ファイルがインターネット経由でパソコンまで転送されてきて(ダウンロードされ)、パソコンのブラウザが表示するため時間が掛かるから」です。
静的レスポンスは、このようにファイルが転送されるだけです。
例えば、企業のホームページの会社概要や事業内容などのように、誰が見る場合でも常に同じ内容を表示する場合に使われます。
だから「静的」です。
動的レスポンスとは?
動的レスポンスとは、一番分かりやすい例は Google 検索です。
Googleのトップページを開き、検索欄に「Yahoo」と入力して「Enter」を押下します。
すると、以下のような結果がブラウザ上に表示されます。
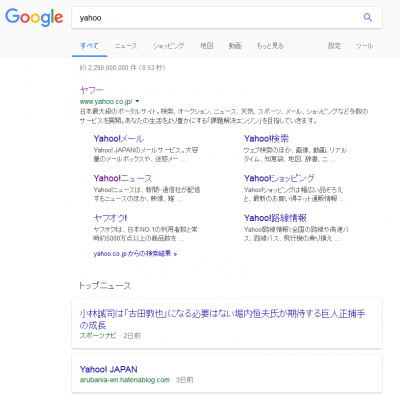
これが「動的レスポンス」です。
Googleは、このページは事前にHTMLでコーディングして index.html などのファイルを作成しておき「Yahoo」と入力するのを待ち構えて表示させたのかというと、そうではありません。
Googleは、検索された「キーワード」を元にGoogleのデータベースから検索して「結果」を返しているのです。
だからあらかじめ「index.html」とか「keyword001.html」などのファイルが用意されていてそのファイルを返しているのではないので「動的」なのです。
以上「ブラウザでインターネットのWebサイトを閲覧する仕組み」を簡単に説明しました。
![]()