今回も引き続き機械学習です。
Ubuntu で Janome と Mecab-ipadic-Neologd を使って形態素解析を試しました。
今回はいわゆる「文学」で形態素解析を試します。
【AWS】【機械学習】Deep Learning AMI(Ubuntu)で【形態素解析】を試した【Part.1】

【AWS】【機械学習】Deep Learning AMI(Ubuntu)で【形態素解析】を試した【Part.2】

【AWS】【機械学習】Deep Learning AMI(Ubuntu)で【形態素解析】を試した(Janomeのインストール)【Part.3】
【AWS】【機械学習】Deep Learning AMI(Ubuntu)で【形態素解析】を試した(Janome&mecab-ipadic-neologd で解析)【Part.4】
目次
補足情報 t.micro だとプログラムが起動できない(killedで終了する)件
AWS の EC2 インスタンスは様々なインスタンスタイプを選択することができます。
「t2.nano」「t2.micro」「t2.small」「t2.medium」など。
「t2.micro」は「無料利用枠の対象」ですが、vCPU が1個、メモリが「1GiB」です。

しかし機械学習で利用する「Janome」は「t2.micro」だとスペックが足りない(メモリが足りない)ため、プログラムを実行しても「killed」で異常終了してしまいます。
【プログラム実行例】
|
ubuntu@AWS_TEST: ~/dl] python3.6 ma-janome.py killed ← プログラムが異常終了してしまいます。 |
そのため、「t2.medium」クラスが必要になります。つまり従量課金されます。
しかし必要最低限しか AWS に利用料金を払いたくない場合は、以下の方法で料金を抑えてみてください。
おそらく起動しっぱなしにするより、7割くらいは料金を削減できると思います。
【AWS】【Python】Lambda で RDS インスタンスを起動・停止するプログラム&スケジュール化手順【2017年最新版】

Python 3.6 から Janome で形態素解析プログラムを実行する
Python 3.6 から Janome で形態素解析をするプログラムです。
【プログラム】
|
ubuntu@AWS_TEST: ~/dl] cat ma-janome.py from janome.tokenizer import Tokenizer ubuntu@AWS_TEST: ~/dl] |
【プログラム実行】
|
ubuntu@AWS_TEST: ~/dl] python3.6 ma-janome.py |
以上が、基本的な Janome の使い方となります。
キーワード出現頻度の解析
青色文庫の作品を使って形態素解析をしてみます。
青色文庫(あおぞらぶんこ)とは?
青空文庫

青空文庫とは、著作権が消滅した作品や、著者が許諾した作品をテキストを公開しているウェブ電子図書館です。
そのため、無料で様々な作品を閲覧することができます。
有名どころでは
- 森鴎外
- 夏目漱石
- 芥川龍之介
- 中島敦
- 太宰治
などの作品が公開されています。
今回はこの青空文庫を使って形態素解析をしてみます。
形態素解析(けいたいそかいせき)とは?
簡単に言うと、テキストを分解することを言います。
例:
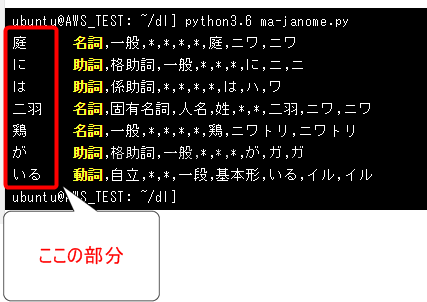
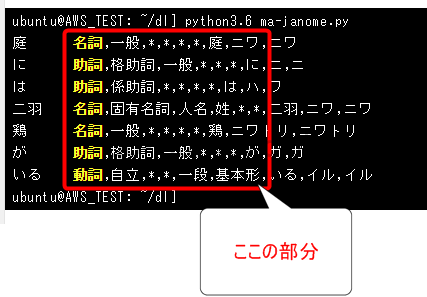
庭には二羽鶏がいる
「庭」「に」「は」「二」「羽」「鶏」「が」「いる」
且つ、テキストを分解してそれぞれの区分を解析します。
例:
|
ubuntu@AWS_TEST: ~/dl] python3.6 ma-janome.py |
上記のように各語がそれぞれ「名詞」や「助詞」など解析されています。
出現頻度が高い「名詞(キーワード)」を抽出
具体的には出現頻度が高い「名詞(キーワード)」を抽出してみます。
【プログラム例】
|
ubuntu@AWS_TEST: ~/dl] cat ginga-count.py from janome.tokenizer import Tokenizer # 銀河鉄道のZIPファイルをダウンロード # ZIPファイル内のテキストファイルを読む # 形態素解析オブジェクトの生成 # テキストを一行ずつ処理 # よく使われる単語を表示 ubuntu@AWS_TEST: ~/dl] |
【プログラム実行例】
|
ubuntu@AWS_TEST: ~/dl] python3.6 ginga-count.py |
何となく「銀河鉄道の夜」らしさを感じます。
- ジョバンニ
- カンパネルラ
- 銀河
- 汽車
- 天の川
- 星
プログラム解説
- xxx.surface ← 表層形(つまり各語彙を取得できます)
- xxx.part_of_speech
プログラムの変更例
次に試しに「名詞」ではなく「固有名詞」に変えてみます。
|
#if ps.find(‘名詞’) < 0: continue ← コメントアウトする if ps.find(‘固有名詞’) < 0: continue ← 「固有名詞」に変えてみる |
【プログラム実行結果】
|
ubuntu@AWS_TEST: ~/dl] python3.6 ginga-count.py |
今度は若干「銀河鉄道の夜」から遠ざかったような気もします。
やはり「銀河」と「汽車」がないからでしょうか。
しかしこの結果を見ても「ジョバンニ」と「カムパネルラ」が主人公であることが分かります。
青空文庫のテキストは「SJIS(Shift JIS)」
今回は「銀河鉄道の夜」のテキストをダウンロードしました。
http://www.aozora.gr.jp/cards/000081/files/456_ruby_145.zip
このテキストファイルは「SJIS(Shift JIS)」です。
普通に cat コマンドで開くと文字化けします。
|
ubuntu@AWS_TEST: ~/dl] cat gingatetsudono_yoru.txt ・ ヘSケフ・ ——————————————————- stF |
テキストの内容を確認したい場合は「iconv」コマンドを使います。
|
ubuntu@AWS_TEST: ~/dl] iconv -f SJIS ‘gingatetsudono_yoru.txt’ ——————————————————- 《》:ルビ |:ルビの付く文字列の始まりを特定する記号 [#]:入力者注 主に外字の説明や、傍点の位置の指定 [#3字下げ]一、午后《ごご》の授業[#「一、午后の授業」は中見出し] 「ではみなさんは、そういうふうに川だと云《い》われたり、乳の流れたあとだと云われたりしていたこのぼんやりと白いものがほんとうは何かご承知ですか。」先生は、黒板に吊《つる》した大きな黒い星座の図の、上から下へ白くけぶった銀河帯のようなところを指《さ》しながら、みんなに問《とい》をかけました。 |
「iconv」コマンドとは?
サーバー系の業務中心の方は「iconv」コマンドをはじめて見るかもしれません。
iconv は「アイコンブ」と読みます。
iconv コマンドは「文字コードを変換して出力する」コマンドです。
|
ubuntu@AWS_TEST: ~/dl] iconv -f SJIS ‘gingatetsudono_yoru.txt’ ——————————————————- |
ちなみに以下のように出力する際の文字コードを指定できます。
|
ubuntu@AWS_TEST: ~/dl] iconv -f SJIS -t utf8 ‘gingatetsudono_yoru.txt’ ——————————————————- |
もし出力する際の文字コードを指定(-t utfなど)しなかった場合は、デフォルトの「utf-8」で出力されます。
参考にした書籍
現在以下の書籍で機械学習のさわり部分を勉強しています。
まだまだ学ぶべき部分は多いですが、「Pythonによるスクレイピング&機械学習 開発テクニック」は機械学習のための様々なライブラリを分かりやすく解説しています。
専門的な部分まで取り扱っていませんが、機械学習初心者にとって、本書は入り口としては最適だと思います。
いきなり難しい専門書を読んでもすぐに挫折すると思うので、最初にこの本を読んでおくのがいいと思います。

![]()
Pythonによるスクレイピング&機械学習 開発テクニック BeautifulSoup,scikit-learn,TensorFlowを使ってみよう![]()
今までの記事
【AWS】【機械学習】Deep Learning AMI(Ubuntu)で【形態素解析】を試した【Part.1】
【AWS】【機械学習】Deep Learning AMI(Ubuntu)で【形態素解析】を試した【Part.2】
【AWS】【機械学習】Deep Learning AMI(Ubuntu)で【形態素解析】を試した(Janomeのインストール)【Part.3】
【AWS】【機械学習】Deep Learning AMI(Ubuntu)で【形態素解析】を試した(Janome&mecab-ipadic-neologd で解析)【Part.4】





