今回は「Firefox」や「Internet Explorer」や「Google Chrome」などのブラウザでインターネットで「Webサイトを閲覧した時の仕組み」について解説します。

日々インフラ系エンジニアとして現場で作業をしていますが、ネットワーク上には
- ファイアウォール
- ルーター
- スイッチ
- サーバー
- ストレージ
など様々なノードが経路上に存在し24時間365日運用管理をしています。
しかしそれでも突然ネットワークがつながらなくなることがあります。
(本当はそんなことがあってはいけませんが)
しかし実際に障害が発生する時は発生します。
現場でよく聞くのが「インターネットにつながらなくなった」「メールが送信できなくなった」などです。
インターネットやメールはビジネスに直結をしているのですぐに復旧させる必要があります。
ただしあるある話ですが「メールが受信できなくなった」という話はあまり聞きません。
その理由は気がつきにくいからです(笑)
話を戻しますがGoogle Chromeなどブラウザで
- インターネットにアクセスする
- Webサイトを閲覧する
場合、内部では何が起きているのでしょうか。
目次
「ブラウザでWebサイトを閲覧する」 ということはどういうことか
「ブラウザでWebサイトを閲覧する」 ということはどういうことかを説明します。
ブラウザを起動し、URLを入力する
Google Chromeを起動し、URLに「http://yahoo.co.jp」を入力してEnterキーを押下(おうか)します。
※IT業界では「押下(おうか)」という用語を使います。押下とはキーボードを押すことです。
ブラウザがURLを分解する
URLを指示されたブラウザは、以下の3つのカテゴリにURLを分解します。
・プロトコル
・ホスト名
・リソース名
TomcatなどWebアプリケーションサーバーなどを使っていると、更に8080などの「ポート番号」の指定も入ってきます。
【例】
http://example.co.jp:8080
例えば本ページのURLは「https://go-journey.club/archives/5771」ですが
プロトコル: https
ホスト名 : go-journey.club
リソース : /archives/5771
と分解できます。
※プロトコルとはネットワークの通信規約を意味する用語です。
通信規約とは、例えばスパイAが「山」と言ったらスパイBが「川」と答えることで、お互いを本物と判断して情報を交換するといったような規則のことです。
もしここで「山」と言ったら「海」と返ってきたら偽物のスパイなので情報は交換しません。(できません)
辞書を見ると、プロトコルとは「外交儀礼」のことを言うようです。
呼び方もプロトコルとか、プロトコールなどと言います。
URLのホスト名からIPアドレスを調べる
ブラウザで「www.yahoo.co.jp」というホストにアクセスしてYahoo!のサイトを閲覧するとします。
この「www.yahoo.co.jp」は「ホスト名」で人間がわかりやすいように付けられた名前です。
ブラウザはインターネット上で目的のコンピュータを見つけなければいけませんが、内部的には「ホスト名」ではなく「IPアドレス」で目的のコンピュータ(サーバー)を探しています。
どうやって「IPアドレス」を調べるのか?
コンピュータはDNS (Domain Name System)というプロトコルを使ってIPアドレスを調べます。
※DNSプロトコルは「53/TCP」もしくは「53/UDP」を利用して通信をします。
例えば「www.yahoo.co.jp」もちゃんとIPアドレスを持っています。
以下「nslookup」コマンドでIPアドレスを確認しています。
|
[test@SAKURA_VPS ~]$ nslookup www.yahoo.co.jp Non-authoritative answer: [test@SAKURA_VPS ~]$ |
上記は「nslookup」コマンドでwww.yahoo.co.jpのIPアドレスを調べた結果です。
もっと分かりやすいコマンド結果が返ってるかと思いましたが、意に反して分かりにくい結果が返ってきました。。
まずチェックする部分は「answer」の部分です。
この「answer」以下に実際にwww.yahoo.co.jpが持っているIPアドレスが表示されます。
Address: 183.79.249.252
すべてのコンピュータは「ホスト名」と「IPアドレス」を持っています。
DNSのシステムでホスト名からIPアドレスを調べて、IPアドレスの情報を取得しています。
その結果、ブラウザは目的のコンピュータにアクセスすることができます。
パソコンのブラウザが、Webサーバーの80番ポートにリクエストを送る
パソコンのブラウザがHTTPプロトコルで、Webサーバーの「80番ポート」にリクエストを送ります。
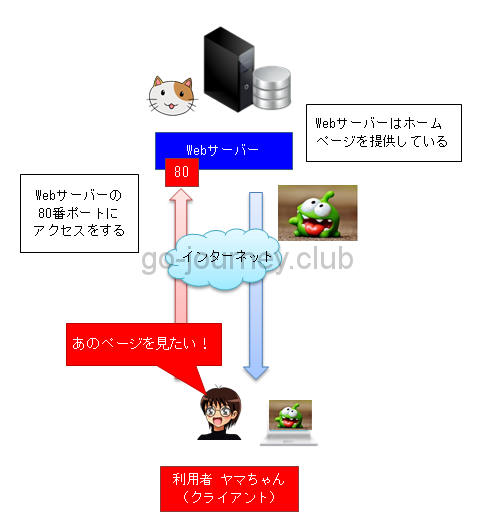
なぜ80番ポートなのか?
理由は、インターネットの一般的な規則で80番と決まっているからです。
所詮一般的なルールだからWebサーバーは80番ポートを使わずに79番ポートを使っても良いです。
そこは自由です。
でも79番ポートで待ち受けているサーバーにアクセスするコンピュータはいないでしょう。
なぜなら一般的な規則から外れているので、ファイアウォールでブロックされる可能性が高いからです。
しかもインターネット経由で初めてアクセスするWebサーバーが実は79番ポートで待ち受けているなど知る由がありません。
当然80番ポートで待ち受けているものだという前提に立っています。
ITエンジニアはインフラ環境を構築しますが、一般的な規則がある前提で設計や構築をしています。
その理由は、一般的な規則を元に設計・構築をした方がトラブルがないからです。
組織によってはセキュリティを考慮して、社内サーバーの10080番ポートへアクセスするように設定しているところもあったりします。
しかしその場合は社内に通知をしていて全員が知っている前提になっています。
要するにみんながポリシーを共有できてさえいれば「何でもいい」のです。
HTTPリクエストとは?
ブラウザはサーバーに対して「HTTPリクエスト」を送ります。
「HTTPリクエスト」は以下のような形式です。
ちなみに以下は「生ログ」です。
|
www.go-journey.club 42.xxx.xxx.xxx – – [07/Oct/2017:04:00:29 +0900] “GET /wp-login.php HTTP/1.1” 200 3048 “-” “Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1” www.go-journey.club 164.xxx.xxx.xxx – – [07/Oct/2017:12:37:48 +0900] “GET /archives/tag/%E5%8F%8D%E5%BE%A9%E3%82%AF%E3%82%A8%E3%83%AA HTTP/1.1” 200 70941 “-” “Mozilla/5.0 (compatible; AhrefsBot/5.2; +http://ahrefs.com/robot/)” |
例えば「www.go-journey.club 164.xxx.xxx.xxx – – [07/Oct/2017:12:37:48 +0900] “GET /archives/tag/%E5%8F%8D%E5%BE%A9%E3%82%AF%E3%82%A8%E3%83%AA HTTP/1.1” 200 70941 “-” “Mozilla/5.0 (compatible; AhrefsBot/5.2; +http://ahrefs.com/robot/)”」の
“GET /archives/tag/%E5%8F%8D%E5%BE%A9%E3%82%AF%E3%82%A8%E3%83%AA HTTP/1.1”
の部分が「HTTP GET」リクエストです。
ちなみに「https://go-journey.club」と頭に付けて
「https://go-journey.club/archives/tag/%E5%8F%8D%E5%BE%A9%E3%82%AF%E3%82%A8%E3%83%AA」
でアクセスが可能です。
「反復クエリ」のタグに行きます。
robotとログが残っているから、スパイダーがアクセスをしたと思います。
ブラウザがサーバーからレスポンスを受け取る
このGETリクエストを受け取ったサーバーはこんなレスポンスを返します。
「HTTP/1.1 200」
HTTP/1.1は、HTTPプロトコルのバージョン1.1という意味です。
ちなみに、以下、RFC2068のドキュメントの抜粋です。
|
Fielding, et. al. Standards Track [Page 6] RFC 2068 HTTP/1.1 January 1997 1 Introduction 1.1 Purpose The Hypertext Transfer Protocol (HTTP) is an application-level protocol for distributed, collaborative, hypermedia information systems. ハイパーテキスト転送プロトコル(HTTP)は、分散型、協調型、ハイパーメディア情報システム向けのアプリケーションレベルのプロトコルです。
HTTP has been in use by the World-Wide Web global information initiative since 1990. HTTPは、1990年以来、World Wide Webのグローバルインフォメーションイニシアチブによって使用されています。
The first version of HTTP, referred to as HTTP/0.9, was a simple protocol for raw data transfer across the Internet. HTTP / 0.9と呼ばれるHTTPの最初のバージョンは、インターネットを介した生データ転送用の単純なプロトコルでした。
HTTP/1.0, as defined by RFC 1945 [6], improved the protocol by allowing messages to be in the format of MIME-like messages, containing metainformation about the data transferred and modifiers on the request/response semantics. RFC 1945 [6]で定義されているHTTP / 1.0は、メッセージがMIMEに似たメッセージの形式になり、要求/応答のセマンティクスで転送されるデータと修飾子についてのメタ情報を含むようにしてプロトコルを改善しました。
However, HTTP/1.0 does not sufficiently take into consideration the effects of hierarchical proxies, caching, the need for persistent connections, and virtual hosts. しかし、HTTP / 1.0では、階層的なプロキシ、キャッシュ、永続的接続の必要性、仮想ホストの影響を十分に考慮していません。
In addition, the proliferation of incompletely-implemented applications calling themselves “HTTP/1.0” has necessitated a protocol version change in order for two communicating applications to determine each other’s true capabilities. さらに、「HTTP/1.0」と呼ばれる不完全に実装されたアプリケーションの普及に伴い、2つの通信アプリケーションが互いの真の能力を判断するためにプロトコルバージョンの変更が必要になりました。 This specification defines the protocol referred to as “HTTP/1.1”. この仕様は “HTTP/1.1″と呼ばれるプロトコルを定義します。 This protocol includes more stringent requirements than HTTP/1.0 in order to ensure reliable implementation of its features. このプロトコルは、その機能の信頼性の高い実装を保証するために、HTTP/1.0より厳しい要件を含んでいます。 Practical information systems require more functionality than simple retrieval, including search, front-end update, and annotation. 実用的な情報システムでは、検索、フロントエンドの更新、アノテーションなど、単純な検索よりも多くの機能が必要です。
HTTP allows an open-ended set of methods that indicate the purpose of a request. HTTPは、要求の目的を示すオープンエンドのメソッドセットを許可します。
It builds on the discipline of reference provided by the Uniform Resource Identifier (URI) [3][20], as a location (URL) [4] or name (URN) , for indicating the resource to which a method is to be applied. これは、メソッドが適用されるリソースを示す場所(URL)[4]または名前(URN)として、URI(Uniform Resource Identifier)[3] [20]によって提供される参照の規律に基づいています。
Messages are passed in a format similar to that used by Internet mail as defined by the Multipurpose Internet Mail Extensions (MIME). メッセージは、MIME(Multipurpose Internet Mail Extensions)で定義されているインターネットメールと同様の形式で渡されます。 |
GETリクエストを受け取ったWebサーバーは、以下のようなレスポンスを返します。
※参考にcurlコマンドを実行してログを表示させています。
|
[test@SAKURA_VPS ~]$ curl -i www.google.co.jp <!doctype html><html itemscope=”” itemtype=”http://schema.org/WebPage” lang=”ja”> <meta content=”「 |

レスポンスをブラウザに表示する
サーバーからのレスポンスを受け取ったブラウザは、ヘッダの最初の部分の「200」という数字でリクエストが成功したことを知ります。
なぜ200番なのかというと、HTTPでは「200番は通信の成功」と決めてあるからです。
ブラウザがレスポンスとして受け取ったHTMLをブラウザ上で表示します。
それをユーザーが目にします。
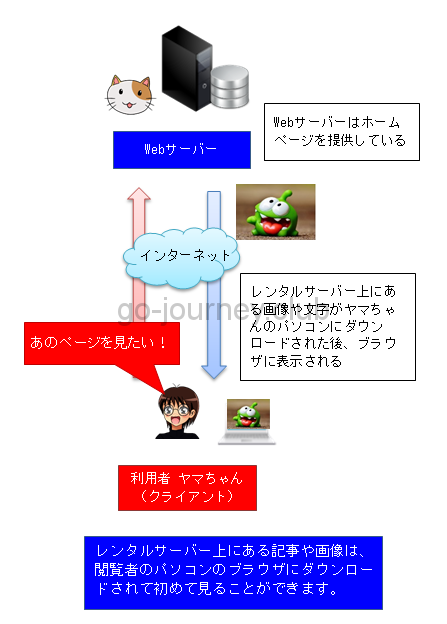

これが「ホームページを見る」ときの大まかな流れです。
サーバーのレスポンスには2種類ある「静的レスポンス」、「動的レスポンス」
レスポンスには2種類あります。
- 静的なレスポンス
- 動的なレスポンス
静的レスポンスとは?
静的なレスポンスの場合、サーバーは、サーバー上に置かれた「index.html」などのHTMLファイルや「xxx.jpg」などの画像ファイルをインターネット経由で送ってきます。
サーバーのハードディスクに入っているファイルがインターネットを通じて、我々のパソコンに転送されてきています。
「このサイトは重い」「この画像ファイルは大きいから表示に時間が掛かる」
という会話を聞いたことがあるかもしれませんが、理由は「5MBもある画像ファイルがインターネット経由でパソコンまで転送されてきて、パソコンのブラウザが表示するため時間が掛かるから」です。
静的レスポンスは、このようにファイルが転送されるだけです。シンプルです。
例えば企業のホームページの会社概要や事業内容などのように、誰が見る場合でも常に同じ内容を表示する場合に使われます。
だから「静的」なのです。
![]()
動的レスポンスとは?
動的レスポンスとは、一番分かりやすい例はGoogle検索です。
Googleのトップページを開き、検索欄に「yahoo」と入力して「Enter」を押下します。
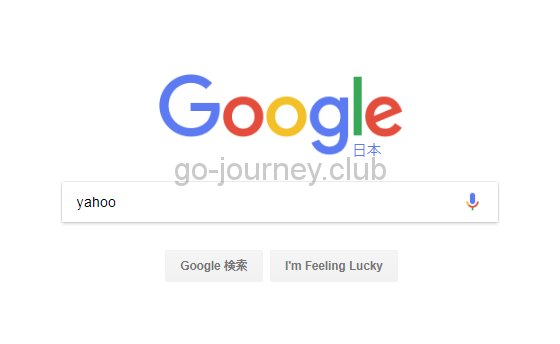

すると、以下のような結果がブラウザ上に表示されます。
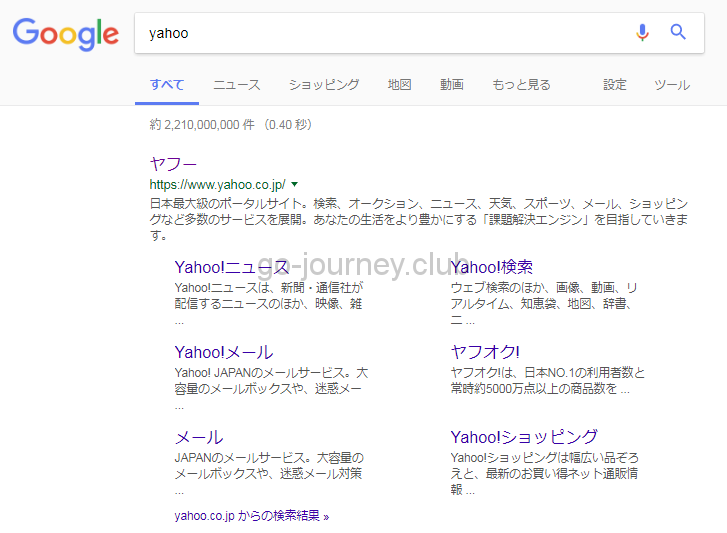

これが「動的レスポンス」です。
Googleは上記のページを事前にHTMLでコーディングして、index.html などのファイルを作成しておいて、今私が「Yahoo」と入力するのを待ち構えて表示させたのかというと、そうではありません。
検索された「キーワード」を元にGoogleのデータベースから「結果」を返しているのです。
だからあらかじめ「index.html」や「keyword001.html」などのファイルが用意されていてそのファイルを返しているのではないので「動的」なのです。
以上が簡単な「ブラウザでインターネットのWebサイトを閲覧する仕組み」です。
![]()
おすすめブラウザは「Google Chrome」
ちなみに私が使うブラウザは「Google Chrome」一択です。
ベンチマークテストをやってみると分かると思いますが、レスポンスがけた違いです。
IEだって細かい設定をすれば(レジストリをいじるとか)、閲覧した時のレスポンスが速くなると思います。
 しかし「細かく設定をしなければいけない」時点で「Google Chrome」よりも使い勝手が悪いです。
しかし「細かく設定をしなければいけない」時点で「Google Chrome」よりも使い勝手が悪いです。
単純にインストールするだけでサクサクとインターネットにアクセスできます。
最近は「AWS」もあらためて素晴らしいサービスだと思っています。
AWSにアカウントを登録します。
その数分後にEC2インスタンスを作り、数分後にはEC2インスタンスにログインしてコマンドが実行できます。
Ansibleなどを利用すれば数分後にはWebサーバーが構築されています。
これは想像以上にすごいことです。






