現在、ソシム株式会社「クジラ飛行机」著の「Pythonによるスクレイピング&機械学習 開発テクニック BeautifulSoup、scikit-learn、TensorFlow を使ってみよう」 で、機械学習を勉強しています。
インフラ系エンジニアでプログラマーとしての業務経験がありませんが、どこまで学習が進むか、どこまで理解できるかチャレンジしようと思っています。
Pythonによるスクレイピング&機械学習 開発テクニック BeautifulSoup,scikit-learn,TensorFlowを使ってみよう
scikit-learn は「サイキット・ラーン」 と読みます。
scikit-learn は Python の機械学習ライブラリです。
機械学習について以前簡単に説明しましたので参照してください。
機械学習とは?
scikit-learn は以下のように分類が豊富にあります。
■分類
サポートベクターマシン ランダムフォレスト Gradient Boosting k近傍法 DBSCAN
■回帰
■クラスタリング
■次元削除
機械学習初心者にとって「scikit-learn」 をお勧めするのは pip コマンドで簡単にインストールができ、機械学習の環境を構築できるからです。
今回は「さくらVPS」 にインストールしてみました。
最初に環境を確認します。
Python 3.6 を使います。
[root@SAKURA_VPS ~]# python3.6
pip コマンドの確認です。
pip コマンドは「pip3.6」 コマンドを利用します。
[root@SAKURA_VPS ~]# pip3.6 -V
pip3.6 コマンドでインストールをします。
scikit-learn、scipy、matplotlib、scikit-image をインストールします。
[root@SAKURA_VPS ~]# pip3.6 install -U scikit-learn scipy matplotlib scikit-image
pandas もインストールします。
[root@SAKURA_VPS ~]# pip3.6 install pandas
padas はデータ解析を支援するライブラリです。
データの読み込みや分割を行います。
機械学習で XOR 演算をやってみます。
XOR は「エックスオア」 と読みます。
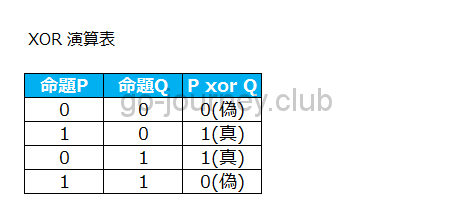
上図が「XOR演算表」になりますが、2つの値を入力した場合、どちらかが「真」でどちらかが「偽」の場合のみ、結果が「真」になります。
逆に両方が「真」、両方が「偽」の場合は結果が「偽」になるという性質があります。
この不思議な論理演算を機械学習プログラムで表現しました。
[root@SAKURA_VPS ai]# vi xor-train.py
# XOR の演算結果・学習器に与える入力データ
# 学習させるためにデータとラベルに分ける
# データの学習
# データを予測
# 正解と合っているか結果を確認
print(“正解率:”, ok, “/”, total, “=”, ok/total)
上記プログラムは以下の書籍を参考にしています。
Pythonによるスクレイピング&機械学習 開発テクニック BeautifulSoup,scikit-learn,TensorFlowを使ってみよう
※ちなみに vi、vim エディタで Python プログラムを書くと、コメントアウト行が青で見にくく感じることがあります。
その場合は自分の好きな色にカスタマイズすることができますので試してみてください。
【Linux】root の vi にカラー(色)を付ける、(root以外でも)vi の色をカスタマイズする(コメントアウトなど)
プログラムを作成したら実行してみます。
[root@SAKURA_VPS ai]# python3.6 xor-train.py
なるほど。
難しいですね(笑)
「正解率: 4 / 4 = 1.0 」なので正解率は100%、全問正解です。
「予測結果: [0 1 1 0] 」は、[P=0, Q=1, result=1, 特に意味なし、フォーマット上のあまり=0] ということだと思います。
つまり scikit-learn の fit() メソッドが4列なので結果も4列で出力されているだけで、クッションの0だと思います。
ただ「~と思う」だと全然違ってしまう可能性があるため、調べました。
fit() メソッドとは
データを与えて学習させる(トレーニングさせる)→ xor_data のデータを与えています。 第一引数に学習するデータの配列、第二引数にラベルの配列を与える→ clf.fit(data, label) の部分です。 学習が完了したら、データを与えられなくても「それらしい」回答を作ることができる→ 予測結果: [0 1 1 0] の部分です。プログラムが勝手に?データを考えて回答をしています。P=0,Q=1 の場合、XOR計算をすると「1(真)」が返ってきますが、プログラムの結果もそうなっています。
です。
ただ、そうはいってもまだまだ敷居が高いです。
Pythonプログラミングは私の一生の趣味になると思いますので!?、諦めずに勉強し続けます。
現在勉強中のテキスト
Python 初心者でも飽きずに勉強できると思います。
インターネット上の情報をプログラムで取得する Web スクレイピングのテクニックもあり、今後記事にする予定ですが夏目漱石の書籍を題材に「形態素解析」をするテクニックも解説しています。
Pythonによるスクレイピング&機械学習 開発テクニック BeautifulSoup,scikit-learn,TensorFlowを使ってみよう
数学初心者向けです。Amazonでは有識者の方からなぜか酷評ですが(ビギナー向けだとか内容が薄いとか)、初心者にとっては解説が丁寧なので分かりやすいです。
ディープラーニングがわかる数学入門