re.sub()での具体的な置換方法です。
【Python】文字列から<特定の文字列>を検索・抽出・置換・削除したい

目次
re.sub() の構文
re.sub() の構文です。
[置換する回数]、[フラグ] はオプションです。
|
import re re.sub(‘パターン(正規表現)’, ‘置換後文字’, ‘置換対象の文字列’, [置換する回数], [フラグ]) |
re.sub() の正規表現は2種類ある
実は re.sub() には2パターンあります。
もし re.sub() で思った通りに置換されない場合は以下のパターンを確認してみてください。
■「r」を付けるパターン
|
#coding:utf-8
info_old = ‘java is language.’
info_new = re.sub(r‘java’, ‘javascript’, info_old) |
【プログラムの実行結果】
|
java is language. |
■「r」を付けないパターン
|
#coding:utf-8
info_old = ‘java is language.’
info_new = re.sub(‘java’, ‘javascript’, info_old) |
【プログラムの実行結果】
|
java is language. |
「r」とは何か?
r は「raw」を表わしています。
Python の raw string 記法です。
rを付けると文字列内ではバックスラッシュ(\)を特別扱いしません。(つまりバックスラッシュそのままの文字であると認識される)
つまりエスケープシーケンスを省略できます。
通常「特殊文字(\'”など)」はバックスラッシュ(\)でエスケープする必要があります。
rを付けなくてもバックスラッシュを何度か付けたり消したりして動作確認をしてみれば最終的にはうまくいくと思いますが、それなら最初から「r」を付けた方がシンプルで思った通りの動きをすると思います。
6.2. re — 正規表現操作
https://docs.python.org/ja/3/library/re.html

公式サイトも raw string を使用することを推奨しています。
確かに以下の「Raw String記法」の解説を読むと r を付けないとバックスラッシュの数が増えて思わぬバグを生みそうです。
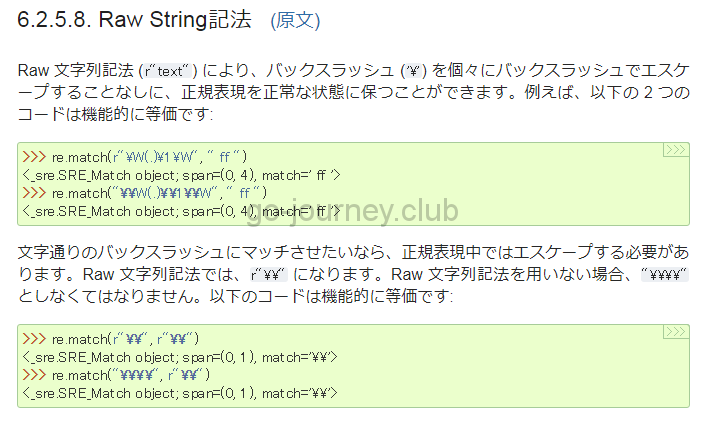
様々なパターン
■【失敗】「r」を付けないパターン
|
#coding:utf-8
info_old = ‘java is \\\language.’
# \\\ を a に変換したい |
■プログラム実行結果
エラーになります。
|
$ python test.py |
■【失敗】「r」を付けるパターン
|
#coding:utf-8
info_old = ‘java is \\\language.’
# \\\ を a に変換したい |
■プログラム実行結果
同じくエラーになります。
|
$ python test.py |
■【成功】「r」を付けるパターン
|
#coding:utf-8
info_old = ‘java is \\\language.’
# \\\ を a に変換したい |
■プログラム実行結果
こちらは想定の動きになりました。
|
$ python test9.py |
※よくよく考えてみたのですが、上の文字列は「\\language」と\が2つしか付いてません。
ということは \ 1つに対して \ 1つが対応している、ということで \ が 4つでうまくいくということです。
■【失敗】「r」を付けないパターン
|
#coding:utf-8 info_old = ‘java is \\\language.’ # \\\ を a に変換したい |
■プログラム実行結果
どうやら\に対して\を重ねればいいというような単純な話ではなさそうです。
|
$ python test.py |
■【成功】「r」を付けないパターン
|
#coding:utf-8 info_old = ‘java is \\\language.’ # \\\ を a に変換したい |
■プログラム実行結果
うまくいきました。
文字列に \\(\\\ではない)が入っていると考えればいいので、\ 1つに対して \ が 4つ必要ということになるのでしょうか。
これでは思いもよらない所でバグを引き起こしそうです。
|
|
参考にしたサイト
6.2. re — 正規表現操作
https://docs.python.org/ja/3/library/re.html





コメント