今回は、よく使うリストの操作について解説します。
特にリストからインデックスを取得し、次の要素に移動するとか、2つ前の要素に移動するなど複雑な処理ができるようになります。
目次
リストとは
リストとは、[](カギ括弧)の中に要素が入っていて、,(カンマ)で区切ります。
【リストの例】
|
[‘りんご’, ‘みかん’, ‘ぶどう’, ‘なし’, ‘すいか’, ‘いちじく’] |
上のリストは果物が入ったリストです。
リストの要素1つ1つに果物(りんごとかみかん)が入っています。
上のリストの例では、要素数は「6」個です。
リストに要素を追加したい
■構文
|
リスト.append(‘要素’) |
■プログラム例
|
list01 = [‘うみ’,’かわ’,’やま’]
list01.append(‘もり’) |
■プログラム実行
|
(pyenv) [test@SAKURA_VPS scraping]$ python test6.py |
テキストファイルを改行ごとにリストにしたい
split関数で「\n(改行)」を指定することで、改行ごとに1要素としてリストに格納されます。
|
f = open(‘test.txt’, ‘r’) print(lines) |
【例】プログラム
|
(pyenv) [test@SAKURA_VPS scraping]$ cat test1.py
f = open(‘test.txt’, ‘r’)
print(lines) |
【例】テキストファイル
|
(pyenv) [test@SAKURA_VPS scraping]$ cat test.txt
(pyenv) [test@SAKURA_VPS scraping]$ |
【実行結果】
|
(pyenv) [test@SAKURA_VPS scraping]$ python test1.py |
リスト形式で出力されています。
【疑問点】なぜ要素が1つ多くなる?【追記 2017年12月9日】
最初は気が付かなかったのですが、よくよく見返してみると要素数が1つ多くなっています。
【例】テキストファイル
|
(pyenv) [test@SAKURA_VPS scraping]$ cat test.txt ← ここに空行が1つあります。 (pyenv) [test@SAKURA_VPS scraping]$ |
【実行結果】
|
(pyenv) [test@SAKURA_VPS scraping]$ python test1.py |
一見すると空の要素が1つ増えただけで問題ないように見えますが、後々これがバグになりトラブルを引き起こす原因になりそうです。
splitメソッド
splitメソッドは何も難しい所はなくて、単純に文字列を任意の区切り文字で区切り、リストに格納するだけのメソッドです。
■splitメソッドの構文
|
‘文字列’.split(‘区切り文字’) |
しかしどこから謎の空の要素が出てきたのでしょうか?
【プログラム】
|
(pyenv) [test@SAKURA_VPS scraping]$ cat test.py # ファイルをオープンして果物を配列(リスト)に代入する print(‘リストの要素数’) |
【ファイルの中身】
|
(pyenv) [test@SAKURA_VPS scraping]$ cat test.txt |
【プログラム実行結果】
|
(pyenv) [test@SAKURA_VPS scraping]$ python test.py |
splitメソッドは区切り文字を入れるとおかしな動作になるので注意
試しに区切り文字を入れずに split() のままで実行してみます。
【プログラム例】
|
(pyenv) [test@SAKURA_VPS scraping]$ cat test.py # ファイルをオープンして果物を配列(リスト)に代入する # 改行コードで分割することを明示 print(‘リストの要素数’)
# ファイルをオープンして果物を配列(リスト)に代入する # 改行コードで分割することを明示しない場合 print(‘リストの要素数’) |
【実行結果】
|
(pyenv) [test@SAKURA_VPS scraping]$ python test.py |
これは「謎」です。
- 分割文字指定 ← 謎の空要素ができる
- 分割文字指定なし ← 空要素はできない
splitメソッドを解説しているサイトを見ると、大体「,(カンマ)」区切りの前提で解説をしているから、逆に「改行」区切りで分割したいケースはないということでしょうか。
カンマ区切りだと、
- 分割文字指定 ← 謎の空要素はできない
- 分割文字指定なし ← 空要素はできない
です。
Python のドキュメントを読んでみた
意味が分からないため、Python のドキュメントを読んでみました。
Python ドキュメント 4. 組み込み型¶(原文)
https://docs.python.jp/3/library/stdtypes.html#str.split
そしたらこんな記述がありました。
「maxsplit が与えられていれば、最大で maxsplit 回分割されます (つまり、リストは最大 <span class="pre">maxsplit+1</span> 要素になります)。」
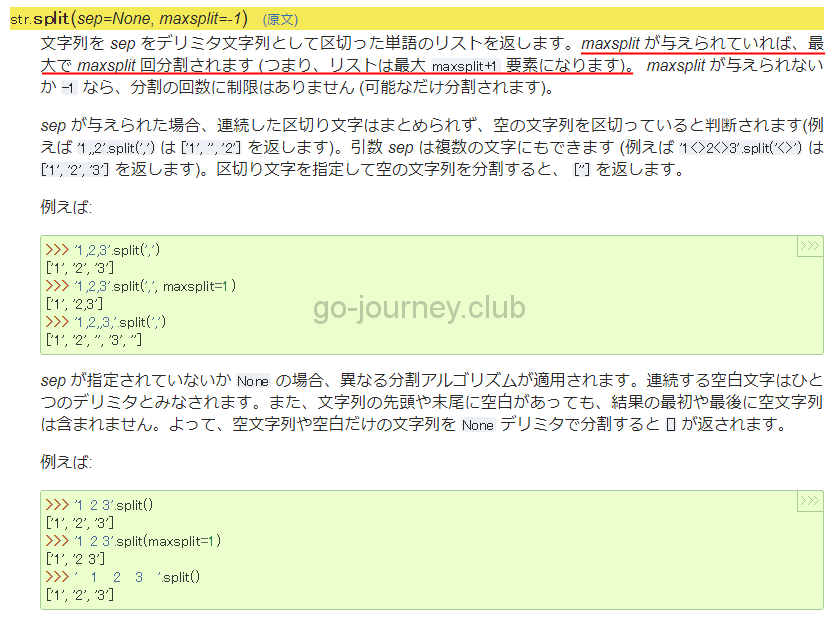
これでしょうか。
つまり、split(‘\n’)というように区切り文字を指定すると、リストの要素数が maxspilit +1となり、合計10個となる。。
しかしカンマだとならないのはなぜでしょうか。
【原因解明】「復帰改行」か「改行」の違いだった
原因解決しました。
catコマンドで改行コードを調べてみたところ、一番最後の行の後ろにちゃんと「改行」コードが含まれていました。
- 改行コード(LF) ← $
- 改行コード(CR) ← ^M
- 改行コード(CRLF) ← ^M$
|
(pyenv) [test@SAKURA_VPS scraping]$ cat -n test.txt |
これは分かりませんでした。
バグなのか仕様なのか悩みましたが、splitメソッド的には正しい動きでした。
split メソッドとしては、「\n(改行コード)」が区切り文字で指定されているので、9行目の「$(LF)」を確認して空の要素を追加していただけだったのです。
リストの各要素に番号を付けて縦に出力したい
リストの各要素に番号を付けて縦に出力させる方法です。
リストの要素数は?
リストの要素数は
len(リスト名) 【例】len(lines) など
で取得できます。
【プログラム例】
|
(pyenv) [test@SAKURA_VPS scraping]$ cat test1.py f = open(‘test.txt’, ‘r’) print(‘リストの要素数’) |
【実行結果】
|
(pyenv) [test@SAKURA_VPS scraping]$ python test1.py |
リスト操作の「enumerate」を使うとインデックスを取得できる
enumerate を使うと要素のインデックスを取得できます。
enumerate ← 【動詞】~を列挙する。~を数え上げる。
【プログラム例】
|
(pyenv) [test@SAKURA_VPS scraping]$ cat test1.py f = open(‘test.txt’, ‘r’) print(‘リストの要素数’) print(‘リストの各要素のインデックスと要素を並べて出力させる’) |
【実行結果】
|
(pyenv) [test@SAKURA_VPS scraping]$ python test1.py |
range を使っても enumerate と同様のことができますが、構文が若干複雑になります。
(一見しただけでは何をしているのか直感的に分かりにくくなる)
そのため分かりやすい「enumerate」がお勧めです。
「enumerate」の意味は「数え上げる」と覚えておけばすぐに何をしているのか分かるようになります。





コメント