よく見かける「©」の文字。この文字は一体何なのでしょうか?
疑問に思ったので調べてみました。
目次
HTML のソースコードに直接記述できない文字がある
HTML のソースコードに直接書けない記号があります。
たとえば、HTML のソースコードに「<test>」と記述すると「タグ」だと認識されてしまいます。
その場合は、以下のように記述します。
- < ← < ← little than ~ の略
- > ← > ← greater than ~ の略
©はマルシーマーク、コピーライトマークなどと呼ばれる
©は HTML では「©」と表現されます。
実際に作ってみます。
|
[root@SAKURA_VPS html]# pwd |
Curl コマンドで表示してみる
まずは curl コマンドでアクセス。
|
[root@SAKURA_VPS html]# curl http://localhost |
ブラウザで表示してみる
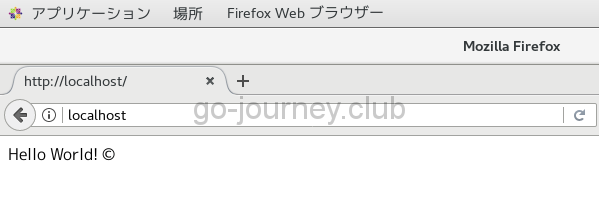
次にブラウザからアクセス。
ちゃんとコピーライトマークで綺麗に表示されています。
Selenium WebDriver で Web スクレイピング
以前、Selenium WebDriver で Web スクレイピングプログラムを作りました。
【Python】Python 3.6 & Selenium WebDriver & PhantomJS でスクレイピング(URLを引数で受け取る)【Part.5】

Webスクレイピング(Selenium WebDriver)でのアクセス。
|
(pyenv) [test@SAKURA_VPS scraping]$ cat text.txt [test@SAKURA_VPS scraping]$ |
コンピュータ上ではコピーライトは3種類で表現される
まとめると
- curlコマンド ← ©
- ブラウザ ← ©
- Webスクレイピング ← c のようなもの(c に見えるが c ではない)
になります。
UTF-8の文字コード表
https://seiai.ed.jp/sys/text/java/utf8table.html
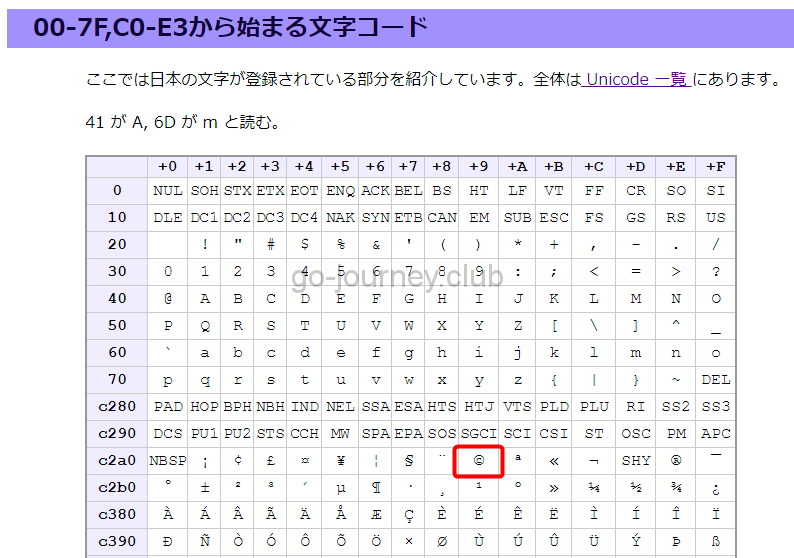
この表を確認すると UTF-8 で「©」は「c2a9」になります。
実際にどうなっているのか文字列をダンプしてみます。
Linuxでのダンプコマンド
Linuxには多くのダンプコマンドがあります。
- hexdump コマンド
- od コマンド
など。
hexdump コマンド
hexdump -C <ファイル> ← 16進数とASCII文字で表示します。
hexdump -c <ファイル> ← 1バイトのASCII文字で表示します。
|
(pyenv) [test@SAKURA_VPS scraping]$ hexdump -C text.txt |
結論を言うと、「c」に見えるが「c」ではなかったということです。





コメント