今回は Python 3.6 & Selenium WebDriver & headless でスクレイピングの2回目です。
普段はインフラ系エンジニアとして現場で業務をしていますが、更にステップアップするためにプログラミングスキルもコツコツと身に付けていこうと考えています。
【Python】Python 3.6 & Selenium WebDriver & headless でスクレイピング【Part.1】

【Python】Python 3.6 & Selenium WebDriver & headless でスクレイピング【Part.2】
【Python】Python 3.6 & Selenium WebDriver & headless でスクレイピング【Part.3】
【Python】Python 3.6 & Selenium WebDriver & PhantomJS でスクレイピング(find系操作)【Part.4】
【Python】Python 3.6 & Selenium WebDriver & PhantomJS でスクレイピング(URLを引数で受け取る)【Part.5】
目次
仮想環境への切り替え
仮想環境に切り替えます。(仮想環境の有効化)
|
[test@SAKURA_VPS pyenv]$ source pyenv/bin/activate |
ただ、思ったのがわざわざ仮想環境に切り替える必要があるのかどうか。
というのも、別途 Python3.6 をインストール済みだからです。
一番シンプルなプログラム
一番シンプルなプログラムです。
何をやってもエラーが出てどうしようもなくなったら、一旦ここに帰ります。
ただしヤフーは表示されるが、他のサイトは拒否られることが多いです。
|
from selenium import webdriver url = ‘https://yahoo.co.jp/’ print(driver.page_source) |
実行例です。
|
(pyenv) [test@SAKURA_VPS scraping]$ python test_selenium.py
<link rel=”icon” sizes=”any” mask=”” href=”//s.yimg.jp/l/cmn/svi/y.svg”> |
Selenium で User Agent を設定する
サイトによっては User Agent がないとはじかれます。
そのため User Agent を設定します。
|
from selenium import webdriver
# Wikiのメインページにアクセス dcap = dict(DesiredCapabilities.PHANTOMJS) |
実行結果です。
|
(pyenv) [test@SAKURA_VPS scraping]$ python test_selenium.py |
本当に設定したユーザーエージェントでアクセスしているか確認
疑問に思ったことが、そもそも本当にこのユーザーエージェントでサイトにアクセスをしているのかどうかということです。
tcpdumpコマンドでパケットをキャプチャしながら、スクレイピングをしてパケットの中身を解析します。
rootアカウントにスイッチして(tcpdumpは一般アカウントでは取得できない)、80番ポートだけ絞ってパケットをキャプチャします。
|
[root@SAKURA_VPS ~]# tcpdump port 80 -i eth0 -w test111.cap |
キャプチャ結果を出力したファイル「test111.cap」をローカルのパソコンに持ってきて、Wiresharkで解析をします。
確かに「”Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/53 “ ”(KHTML, like Gecko) Chrome/15.0.87″」の文字列があるので、指定したユーザーエージェントでアクセスをしているようです。
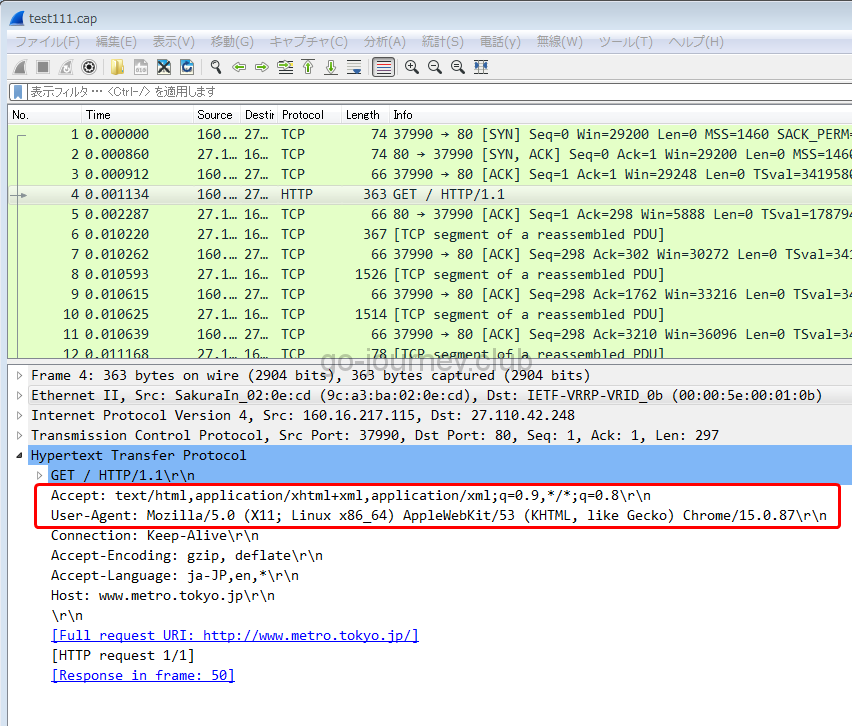
念のため、ユーザーエージェントの文字列を変更してみます。
|
from selenium import webdriver url = ‘http://www.metro.tokyo.jp/’ dcap = dict(DesiredCapabilities.PHANTOMJS) |
再度 tcpdump をしながらプログラムを実行します。
|
[root@SAKURA_VPS ~]# tcpdump port 80 -i eth0 -w test11111.cap |
パケットの中身を見ると確かにユーザーエージェントは書き変わっています。
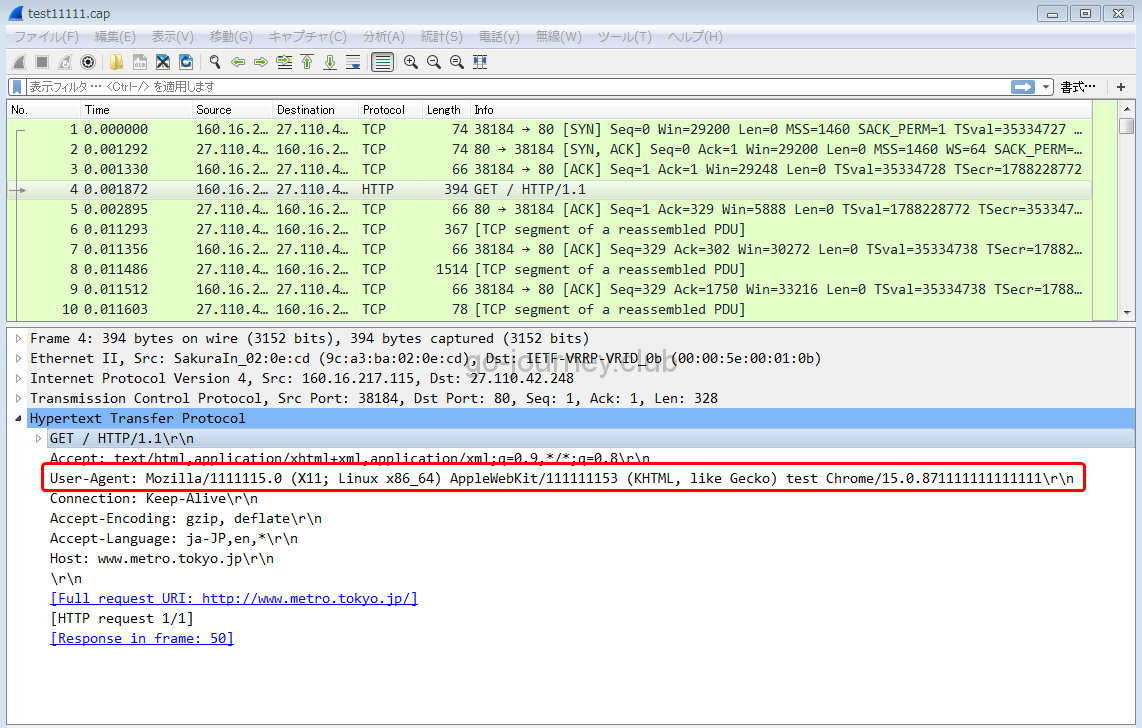
DesiredCapabilitiesとは
DesiredCapabilitiesでユーザーエージェントを指定していますが、DesiredCapabilitiesを利用することで
- ブラウザの種類(Firefox、Google Chromeなど)
- ブラウザのオプション
- ブラウザのバージョン
- ユーザーエージェント
など様々な設定をすることが可能です。
Python 辞書型
- {}で囲む
- keyとvalue(キーと値)の組み合わせ
- keyとvalueは「:(コロン)」で区切る
- keyとvalueのセットは、「,(カンマ)」で区切る
サンプルプログラム
|
(pyenv) [test@SAKURA_VPS scraping]$ vi test_dict.py test = {‘NHK’:1,’日テレ’:4,’テレビ朝日’:5,’TBS’:6,’テレビ東京’:7,’フジテレビ’:8}
print(test) |
プログラムを実行します。
|
(pyenv) [test@SAKURA_VPS scraping]$ python test_dict.py |
Firefox を使用した際の「No such file or directory: ‘geckodriver’: ‘geckodriver’」のエラー出力
geckodriverがインストールされていないと以下のような「FileNotFoundError: [Errno 2] No such file or directory: ‘geckodriver’: ‘geckodriver’」が出力されます。
|
(pyenv) [test@SAKURA_VPS scraping]$ python test_selenium.py During handling of the above exception, another exception occurred: Traceback (most recent call last): (pyenv) [test@SAKURA_VPS scraping]$ |
Selenium はインタフェースとしてのブラウザのドライバを必要とします。
例えば、Firefox の場合は「geckodriver」ドライバを必要とします。
【例】
Firefoxの場合
https://github.com/mozilla/geckodriver/releases
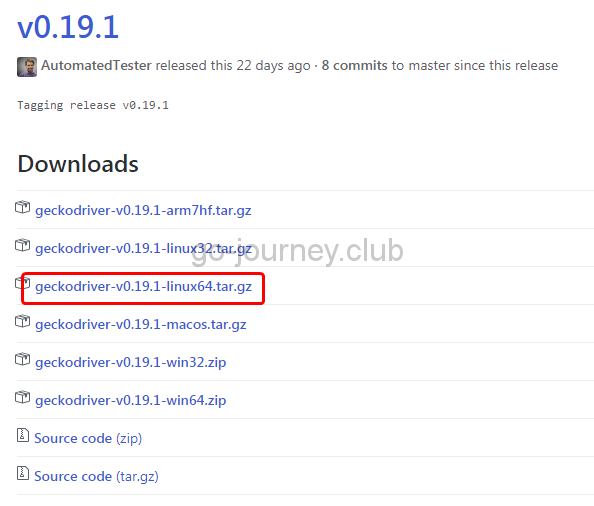
「geckodriver-v0.19.1-linux64.tar.gz」をダウンロードします。
|
(pyenv) [test@SAKURA_VPS ~]$ wget https://github.com/mozilla/geckodriver/releases/download/v0.19.1/geckodriver-v0.19.1-linux64.tar.gz 100%[==============================================================>] 2,301,226 1.24MB/s 時間 1.8s 2017-11-23 00:35:01 (1.24 MB/s) – `geckodriver-v0.19.1-linux64.tar.gz’ へ保存完了 [2301226/2301226] (pyenv) [test@SAKURA_VPS ~]$ |
ダウンロードした「geckodriver-v0.19.1-linux64.tar.gz」を展開して「/usr/local/bin」にコピーします。
|
(pyenv) [test@SAKURA_VPS ~]$ tar xvfz geckodriver-v0.19.1-linux64.tar.gz |
firefoxのプロセスをまとめてkillする
何度かデバッグを繰り返していると以下のように終了しないfirefoxのプロセスが溜まります。
|
(pyenv) [test@SAKURA_VPS scraping]$ ps -ef | grep firefox |
まとめてプロセスを kill するためには pgrep でプロセスを検索して、xargs で kill コマンドを実行して kill します。
|
(pyenv) [test@SAKURA_VPS scraping]$ pgrep firefox | xargs kill -9 |
現在勉強している本
Seleniumでどうすればいいのか分からなくなった時に読む本です。
サンプルプログラムは Java で書かれていますが、オプションや構文などは Python でも役に立ちます。

![]()
Pythonでどうやって Web スクレイピングをすればいいのか参考になる本です。こちらもどうすればいいのか迷った時に読む本です。

![]()
シリーズ一覧
【Python】Python 3.6 & Selenium WebDriver & headless でスクレイピング【Part.1】
【Python】Python 3.6 & Selenium WebDriver & headless でスクレイピング【Part.2】
【Python】Python 3.6 & Selenium WebDriver & headless でスクレイピング【Part.3】
【Python】Python 3.6 & Selenium WebDriver & PhantomJS でスクレイピング(find系操作)【Part.4】
【Python】Python 3.6 & Selenium WebDriver & PhantomJS でスクレイピング(URLを引数で受け取る)【Part.5】
まとめ
全くまとまりのない記事になってしまいましたが、コツコツとノウハウを貯めていきます。
まだまだ先は長くなりそうです。




