レンタルサーバーでもWebサーバーでも日々運用していると、急にレスポンスが悪くなったり、タイムアウトしたりでページの閲覧が遅く(重く)なったりします。
今回は、サーバーの負荷状態について調査する方法を解説します。
原因の仮説を立てられるようになると素早く対応することもできます。
目次
サーバーの負荷状態の調査方法
「何が原因で処理が遅延しているのか?」
まずは切り分けをする必要があります。
大雑把にカテゴリ分けをしてみました。
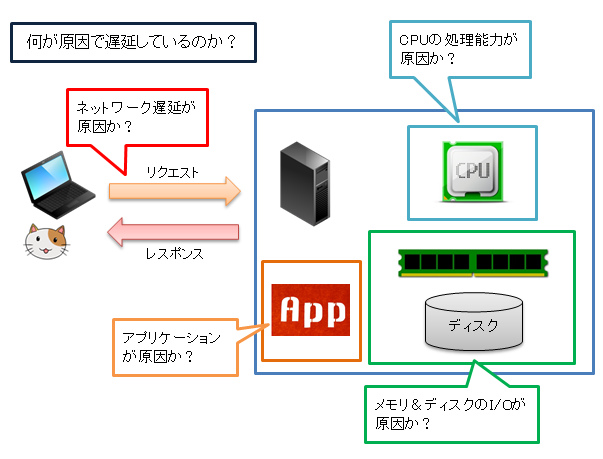
上図ですが以下のようにカテゴライズできます。
- ネットワークの遅延
- アプリの不具合
- CPUの処理能力が低い
- メモリ&ディスクのI/Oの遅延
原因が分かれば対処ができます。
例えば「メモリを増設する」「ディスクをSSDに変更してみる」「CPUを高性能なものに変える」など具体的な対処ができます。
その原因の特定を以下のコマンドで見つけていきます。
ロードアベレージ(Load Average)
まずはロードアベレージで「システム全体の負荷状況」を見ます。
ただしロードアベレージだけで「ボトルネックの原因」は分かりません。
本当にサーバーに負荷が掛かっているのか?それともネットワークなど外的要因なのか?ロードアベレージを確認してあたりをつけます。
■ロードアベレージ(load average)とは
ロードアベレージはシステム全体の負荷状況を表す指標です。
ロードアベレージ、イコール、Linux のシステム負荷と考えてもいいと思います。
ちなみに Windows の場合は、「ロードアベレージ」を確認できるコマンドやツールはありません。
Windows の「タスクマネージャ」を見れば負荷状況を確認できますが「ロードアベレージ」は確認できません。
「CPU 使用率」や「メモリ使用率」で判断します。

ロードアベレージは、1 CPU における単位時間あたりの実行待ちとディスク I/O 待ちのプロセスの数で表されます。
つまり、ロードアベレージは Linux システムの一定期間のシステム負荷を数値化したものと言えます。
Linux システムがアイドル状態のコンピュータのロードアベレージ(負荷数)は 0 です。
以下は、ほとんどシステム負荷がない状態の top コマンドです。
|
top – 13:53:03 up 1 min, 1 user, load average: 0.12, 0.05, 0.02 |
vmstat コマンドで確認しほとんどシステム負荷が 0 の状態です。
|
[ec2-user@RedHat8SV ~]$ vmstat 1 |
システム負荷がある場合は、CPU を使用している、または CPU を待機しているプロセスが多数存在します。
top コマンドの場合は、過去 1分間、5分間、15分間のロードアベレージの数値が表示されます。
■/proc/loadavg での表示
|
[ec2-user@RedHat8SV ~]$ cat /proc/loadavg |
最初の 3 つのカラムは、過去 1 分間、5 分間、15 分間の CPU 及び IO の使用率の測定値を示しています。
第 4 のカラムは、現在実行中のプロセス数とプロセスの合計数を示しています。
最後のカラムは、最後に使用されたプロセスの ID を示しています。
システム全体のスループット(単位時間当たりの処理量、例えば 1秒間に 100件処理をする場合は 100件/秒)を上げたい場合はロードアベレージを下げます。
- ロードアベレッジ高い → システムに負荷がある状態
- ロードアベレッジ低い → システムに負荷がない状態
ロードアベレージの見方
実際はここまで単純な話ではありませんが、単純化するとこんな感じです。
- 1 CPU ← ロードアベレージ 1 ← 100% 効率よく利用している
- 1 CPU ← ロードアベレージ 2 ← 負荷が掛かっている
- 4 CPU ← ロードアベレージ 4 ← 100% 効率よく利用している
- 10 CPU ← ロードアベレージ 5 ← 半分の CPU リソースを利用している
- 100 CPU ← ロードアベレージ 100 ← 100% 効率よく利用している
ロードアベレージは低いがシステムは遅い場合
サーバーに原因はなく、「ソフトウェア」「ネットワーク」「リモートホスト」の原因を疑います。
ロードアベレージが高くシステムが遅い場合
「CPU」か「I/O」か切り分けをします。
topコマンドを実行する
まずは top コマンドを実行します。
オプション、引数なしで top コマンドを実行します。
コマンドを実行すると、実行中のプロセスで CPU の負荷が大きいものから順に表示され、情報は自動的に更新されます。
初期設定では 5秒ごとに表示が更新されますが、[SPACE] キーを押下することにより表示を更新することができます。
表示を終了するには [q] または [Ctrl] + [c] を押してください。
|
① top – 20:39:08 up 33 days, ② 23:48, ③ 1 user, ④ load average: 0.01, 0.04, 0.05
26 27 28 29 30 31 32 33 34 35 36 37 |
①topコマンドが実行された時刻(up 33daysは33日間システムが起動しているということ)
②稼働時間(コマンド実行からの表示時問)
③ログインユーザ数
④実行待ちジョブ(プロセス)の平均数(直前1分間/直前5分問/直前15分間の平均数)
この数値が多いということは、何かが原因で実行を待たされているプロセスが多いということです。
その原因は「予想1.他のプロセスにCPUが取られている」「予想2.I/Oが遅くて待たされている」などが考えられます。
※1CPUでロードアベレージ1と、4CPUでロードアベレージ4は論理的には同じ負荷。つまり、きっちりリソースを使っている(100%)ということになる。CPUの1コア数に対する数値であることに注意。
※プロセス、タスク、ジョブ様々な呼び方がある。
⑤Tasks プロセス総数
⑥running 稼働プロセス数
⑦sleeping 待機プロセス数
⑧stopped 停止プロセス数
⑨zombie ゾンビプロセス数
⑩us ユーザに費やされたCPU時間の比率
Time spent in user space
⑪sy systemプログラムによる使用率
Time spent in kernel space
⑫ni 優先プロセスに費やされたCPU時間の比率
Time spent on low priority processes
⑬id 持機となっているCPU時間の比率
Time spent in idle operations
⑭wa I/O 処理の完了を待っていた時間
wa: is meaning of “iowait”
Time spent on waiting on IO peripherals (eg. disk)
⑮hi ハードウェア割込み要求処理に費やされたCPU 時間
Time spent handling hardware interrupt routines
⑯si ソフトウェア割込み要求処理に費やされたCPU 時間
Time spent handling software interrupt routines
⑰st タイムスタンプを使用したカーネル内のsoftirqタイム処理に費やされたCPU時間の比率
Time in spent on involuntary waits by virtual cpu while hypervisor is servicing another processor (stolen from a virtual machine)
⑱total 全メモリ容量(単位:キロバイト)
⑲free 使用中のメモリ容量(単位:キロバイト)
⑳used 空きメモリ容量(単位:キロバイト)
21 buff/cache バッファメモリ容量(単位:キロバイト)
22 Swap 全スワップメモリ容量(単位:キロバイト)
23 free 使用中スワップメモリ容量(単位:キロバイト)
24 used 空きスワップメモリ容量(単位:キロバイト)
25 avail Mem キャッシュメモリ容量(単位:キロバイト)
26 PlD プロセス番号
27 USER プロセス実行ユーザ名
28 PR プロセスの優先順位
29 NI プロセスの実行優先度(ナイス値)
30 VIRT(SIZE) タスクコード、データ、スタックスペースのサイズ
31 RSS(RES) プロセスの物理メモリ使用量(単位:キロバイト)
32 SHR (SHARE) プロセスの共有メモリ使用量(単位:キロバイト)
33 S(TAT) プロセスのステータスを表示
S 停止状態(スリープ中)
D 継続停止状態(割り込み不可能なスリープ中)
P 稼働状態(実行中)
Z ゾンビ状態(ゾンビブロセス)
T 停止またはトレース状態
< ナイス値が – で実行中(負のナイス値を持つプロセス)
N ナイス値が + で実行中(正のナイス値をもつプロセス)
W スワップアウト状態(カーネルプロセスに対しては正しく動作しない)
LIB 共有ライブラリが使用するページサイズ
34 %CPU CPU占有率(表示が更新されてからタスクがCPUを占有していた割合)を表示
35 %MEM 実メモリ占有率(表示が更新されてから物理メモリを占有していた割合)を表示
36 TIME+(TIME) プロセス開始からの経過時間(単位:秒)を表示
37 COMMAND 実行コマンド名を表示
ロードアベレージの見方
man uptime コマンドの抜粋です。
|
現在時刻、システム起動からの時間、システム上にいるユーザ数、および直近1、5、15分間の実行キューに存在するジョブの平均数を表示します。 割り込み不可のスリープ状態にあるプロセス数も平均負荷率に数えられます。 FILE としては /var/log/wtmp が一般的です。 |
日本語だと説明が端折りすぎなので英語で「man uptime」の結果を表示させます。
|
DESCRIPTION 稼働時間は、次の情報を1行で表示します。 The current time, how long the system has been running, how many users are currently logged on, and the system load averages for the past 1, 5, and 15 minutes. This is the same information contained in the header line displayed by w(1). これは、w(1)によって表示されるヘッダー行に含まれる同じ情報です。 System load averages is the average number of processes that are either in a runnable or uninterruptable state. システムロードアベレージ(負荷平均)は、「実行可能」または「中断不可状態」のプロセスの平均数です。 A process in a runnable state is either using the CPU or waiting to use the CPU. 実行可能状態のプロセスは、CPUを使用しているか、またはCPUを使用するのを待っています。(CPU を使用している状態でも「実行可能状態」と表現される) A process in uninterruptable state is waiting for some I/O access, eg waiting for disk. uninterruptable 状態のプロセスは、I/O アクセスを待っています(たとえば、ディスクを待っています)。 The averages are taken over the three time intervals. 平均は、3つの時間の間隔にわたって取られます。 Load averages are not normalized for the number of CPUs in a system, so a load average of 1 means a single CPU system is loaded all the time while on a 4 CPU system it means it was idle 75% of the time. ロードアベレージは、システム内のCPU数で正規化されていないため、負荷平均は1つのCPUシステムが常にロードされることを意味し、4CPUシステムでは75%のアイドル時間を意味します。 |
緑色の部分ですが、「ロードアベレージは、システム内の CPU 数に対して正規化されていないため、1つの CPU でロードアベレージが 1の場合は、常にプロセスが CPU にロードされることを意味し、4 CPU でロードアベレージが 1の場合は、75%のアイドル時間を意味します。」と読めます。
例えば、4 CPU のシステムで、ロードアベレージが 1 だとすると、75% の CPU がアイドル状態ということです。
だから、CPU が 4コアでロードアベレージが 3 とか 4 だとしても、直ちに「ロードアベレージが高い」とは言えません。
man top
manコマンドでtopコマンドの勉強をします。
|
TOP(1) Linux User’s Manual 名前 書式 昔からのスイッチ ‘-‘ と空白の指定は任意である。
説明 Linux カーネルが現在管理しているタスクの一覧だけでなく、システムの概要情報も表示できる。 表示されるシステムの概要情報のタイプと各タスクについて表示される情報のタイプ・順序・サイズは、 ユーザーが全て設定可能で、その設定は次に起動したときにも保存できる。 このプログラムはプロセスの操作に関する限定された対話型インタフェースだけでなく、 個人用の設定についての特に拡張されたインタフェースも提供している。 — 操作の全ての面についての包括的なインタフェースを提供している。 新しい名前 (エイリアスでもよい) は、top の表示に反映され、 設定ファイルを読み書きの際に使用される。 概要 操作 終了させるときには、代わりとして、単純に昔からの割り込みキー (‘^C’) を使うこともできる。 最初に top を起動する場合、 昔からの以下のスクリーンの要素が表示される: 1) サマリーエリア; 2) メッセージ/プロンプト行 3) カラムヘッダ; 4) タスクエリア。 しかし、以前の top と比較すると、いくつかの違いがある。 ハイライト その他の要素の値のみがハイライトされる。 タスクエリア: 実行中 (または実行の準備がされている) のタスクがハイライトされる。
これらのプロセスを強調する唯一の手段は太字で表示することである。 内容/ラベル シンボリックリンク名またはエイリアスが表示される場合もある。 Cpu(s) 状態ラベルは他のものが表示される可能性を暗に示している。 メモリ統計では小文字 ‘k’ が使用される。 カラムヘッダ: 新しいフィールドといくつかの変更されたラベルが表示される。 top をカスタマイズすれば新しいフィールドが更に表示される。 注意: top の表示は 512 文字に制限される。 全てのフィールドを表示するためには最低 160 文字が必要である。 残りの幅は ‘Command’ カラムに使用できる。
起動時のデフォルト値 しかし、アスタリスク (‘*’) の付いたコマンドはコマンドラインで上書きできる。 全体のデフォルト
サマリーエリアのデフォルト
タスクエリアのデフォルト 1. コマンドラインオプション -hv | -bcisS -d delay -n iterations -p pid [,pid…] 一般には必須とされているスイッチ (‘-‘) と空白でさえ、完全にオプションである。 -b : バッチモード 操作 top の出力を他のプログラムやファイルに送る場合に役立つ。 このモードでは、top は入力を受け付けず、 ’-n’ コマンドラインオプションで設定された繰り返し回数に達するか、kill されるまで実行を続ける。 -c : コマンドライン/プログラム名 トグル よって、top がコマンドラインを表示していた場合は、プログラム名を表示する。 プログラム名を表示していた場合は、コマンドラインを表示する。 -d : 遅延時間 間隔: -d ss.tt (秒.1/10秒) ユーザー個人の設定ファイルにあるこれに対応する値、または起動時のデフォルトの値を上書きする。 実行後に対話的コマンド ‘d’ または ‘s’ で変更できる。 小数点以下の秒も指定できるが、負数は許可されない。 しかし全ての場合において、top が「セキュアモード」で実行されているときには、このような変更は禁止されている。 ただし root の場合 (かつコマンドラインオプション ‘s’ が使われていない場合) は除く。 「セキュアモード」についてのより詳しい情報は、「5a. システム設定ファイル」の話題を参照すること。 -h : ヘルプ -i : アイドルプロセス トグル トグルが Off の場合、アイドルタスクまたはゾンビタスクは表示されない。 -n : 繰り返し回数 制限: -n number -u : ユーザーを指定して監視する: -u somebody -U : ユーザーを指定して監視する: -U somebody 実・実効・保存・ファイルシステム UID とマッチするものが選ばれる。
-p : PID を指定して監視する: -pN1 -pN2 … または -pN1, N2 [,…] このオプションを 20 個まで指定するか、コンマで区切った 20 個までのプロセス ID を指定することができる。 両方を混ぜて使用することもできる。 これはコマンドラインオプションでのみ指定できる。 通常の操作に戻したい場合は、top を終了して再起動する必要はなく — 対話的コマンド ‘=’ を実行するだけでよい。 -s : セキュアモード 操作 このモードはシステムの設定ファイルで制御する方が、更に良い。 (「5. ファイル」の話題を参照すること)。 -S : 累積時間モード トグル 「累積モード」が On の場合、各プロセスはそのプロセスとそのプロセスの終了した子プロセスで使われた cpu 時間とともに表示される。 -v : バージョン -M : メモリ単位を検出 2. フィールド / カラム これらのフィールドは、対話的コマンド ‘o’ (フィールドの順序変更) で指定できる位置に関わらず、以下で示す文字と常に関連付けられている。 全てのフィールドはソート対象として選択可能であり、降順でソートするか昇順でソートするかを制御できる。 ソート機能についての詳しい情報は「3c. タスクエリアコマンド」の話題を参照すること。 a: PID — プロセス ID 定期的に同じ番号が使われるが、0 から再スタートすることはない。 b: PPID — 親プロセスのプロセス ID c: RUSER — 実ユーザー名 d: UID — ユーザー ID e: USER — ユーザー名 f: GROUP — グループ名 g: TTY — 制御端末 通常はプロセスが開始されたデバイス (シリアルポート、疑似端末 (pty) など) であり、入出力に使われる。 しかしタスクは端末に関連付ける必要はなく、その場合は ‘?’ が表示される。 h: PR — 優先度 i: NI — nice 値 負の nice 値は高い優先度を意味し、正の nice 値は低い優先度を意味する。 このフィールドが 0 の場合、タスクの割り当て (dispatchability) を決定する際に 優先度を調整していないこと意味する。 j: P — 最後に使用された CPU (SMP) カーネルはわざと weak affinity を使っているので、本当の SMP 環境では、この値は頻繁に変わりやすくなる。 また実行中の top の動作そのものが (cpu 時間に対する余分な要求となることによって) weak affinity を壊すかもしれず、プロセスの CPU 変更がより多くなるかもしれない。
k: %CPU — CPU 使用率 総 CPU 時間のパーセンテージで表される。 本当の SMP 環境では、「Irix モード」が Off の場合、top は「Solaris モード」で操作し、 タスクの cpu 使用率は総 CPU 数で割り算される。 ´Irix/Solaris’ モードは対話的コマンド ‘I’ でトグルできる。 l: TIME — CPU 時間 「累積モード」が On の場合、 各プロセスは終了した子プロセスが使った cpu 時間とともにリストされる。 「累積モード」はコマンドラインオプションと対話的コマンドの ‘S’ でトグルできる。 このモードについての更なる情報は、対話的コマンド ‘S’ を参照すること。 m: TIME+ — CPU 時間 (1/100 単位) n: %MEM — メモリ使用率 (RES) o: VIRT — 仮想イメージ (kb) コード・データ・共有ライブラリ・スワップアウトされているページが含まれる。 VIRT = SWAP + RES. p: SWAP — スワップされたサイズ (kb) q: RES — 常駐サイズ (kb) RES = CODE + DATA. TP 3 r: CODE — コードサイズ (kb) 実行可能コードに割かれる物理メモリの総量。 「テキスト常駐サイズ (text resident set)」または TRS とも呼ばれる。 s: DATA — 「データ+スタック」のサイズ (kb) 「データ常駐サイズ (data resident set)」または DRS とも呼ばれる。 t: SHR — 共有メモリサイズ (kb) 他のプロセスと共有される可能性のあるメモリを単純に反映している。 u: nFLT — ページフォールト回数 ページフォールトは、現在、アドレス空間にない仮想ページに対してプロセスが読み書きしようとしたときに起こる。 v: nDRT — ダーティページ数 ダーティページは、対応する物理メモリの場所が他の仮想ページで使用される前に、ディスクに書き込まれなければならない。 w: S — プロセス状態 実行中と表示されるタスクは「実行準備済み」と考えるのがより正しいだろう。 – タスクの task_struct は Linux の実行キューで表現されている。 本当の SMP マシン以外でさえ、top の遅延間隔と nice 値に依っては、この状態のタスクを非常に多く目にするだろう。
x: Command — コマンドラインまたはプログラム名 コマンドラインとプログラム名は、 コマンドラインオプションと対話的コマンドの ‘c’ でトグルできる。 コマンドラインの表示を選択した場合、 (カーネルスレッドのように) コマンドラインのないプロセスは、 以下の例のように、プログラム名だけが括弧で括られて表示される。 コマンドライン・プログラム名の表示が現在のフィールド幅に対して長すぎる場合は、切り詰められる場合がある。 フィールド幅はその他に選択されているフィールド・フィールドの順番・ 現在のスクリーン幅に依存する。 注意: ‘Command’ フィールド/カラムは固定幅でないという点が特殊である。 表示の際、このカラムは残りの全てのスクリーン幅 (最大 512 文字) が割り当てられる。 これは、プログラム名からコマンドラインへの切り替えで文字数が増える場合に備えるためである。 y: WCHAN — スリープしている関数 カーネル関数の名前またはアドレスが表示される。 実行中のタスクでは、このカラムにダッシュ (‘-‘) が表示される。 注意: このフィールドを表示すると、top 自身のワーキングセットが 700Kb 増加する。 このオーバーヘッドを減らす唯一の方法は、top を停止して再起動することである。 z: Flags — タスクフラグ これらのフラグは公式には <linux/sched.h> に書かれている。 公式なものではないが、「フィールド選択」スクリーンと「フィールド順序指定」スクリーンにも説明がある。 |
topコマンドを「回数指定」&「回数指定」して実行する(例:5秒間隔で1時間topコマンドを実行したい)
たとえば、負荷調査をする時に、深夜帯のバッチ処理時に top コマンドを5秒おきに1時間実行して、その結果をファイルに保存して後から調査したい場合などあります。
以下例としての要件です。
- 深夜0:00~1:00までの1時間
- 5秒間隔でtopコマンドを実行
- cronでキックしたい
- 結果をファイルに保存したい
コマンド自体は以下のようになります。
|
# top -d 5 -n 720 -b > top1h.txt |
-d:
topコマンドを実行する間隔を(秒)で指定します。
今回は5秒間隔なので「-d 5」を指定します。
-n:
繰り返し回数を指定します。
top が終了するまでの繰り返し回数を指定します。
今回は5秒間隔で1時間なので、「60(秒)×60(分)÷5(秒)=720回」になります。
-b:
top を「バッチモード」で起動します。
top の出力を他のプログラムやファイルに送る場合に役立ちます。
午前0:00から実行したいので、crontabには以下の設定を入れます。
|
$ crontab -e
0 0 * * * top -d 5 -n 720 -b >> top1h.txt |
この設定は、毎日0:00からtopコマンドを実行して1時間後に終了します。
cronの詳しい解説です。

I/O負荷が高い場合
CPUに負荷が掛かっていない、しかしロードアベレージが高い場合は「I/O負荷」を疑います。
I/O負荷が高くなる原因
- メモリが少なくてスワップが発生してディスクアクセスが頻発している
- プログラムからの入出力が多くて負荷が高い
まずは、以下の2つのコマンドでスワップの発生状況を調べます。
- free
- vmstat
スワップとは?
スワップとは「実メモリ」と「仮想メモリ」の入れ替え作業のことを言います。
「仮想メモリ」はHD(ハードディスク)上に作成されます。
仮想メモリを「スワップ領域」とも言います。
仮想メモリは、OS上で見える使用可能メモリを増やすために使われるディスク領域のことです。
Linux では、仮想メモリ(スワップ領域)は、いわゆるスワップ(実メモリと仮想メモリの総入れ換え)ではなくページングに使われます。
ページングとは、物理メモリが少なくなるとメモリページをページ単位でディスクに書き込み、必要に応じて物理メモリに読み戻す処理です。(ページインとページアウト)
freeコマンド
| # free total used free shared buff/cache available Mem: 500452 172200 15676 28920 312576 260840 Swap: 4194300 126968 4067332 |
※freeコマンドの単位は「KB」がデフォルトです。
-k, –kilo
Display the amount of memory in kilobytes. This is the default.
■Mem
total 全メモリ容量が表示されます。OSが認識している物理メモリサイズです。
Total installed memory (MemTotal and SwapTotal in /proc/meminfo)
used 使用中のメモリ容量が表示されます。OSが利用しているバッファ/キャッシュメモリ(buff/cache)は含まれません。
Used memory (calculated as total – free – buffers – cache)
total – free – buff – cache の計算が「used memory」になります。
【例】
500452 – 15676 – 312576(buff/cache合計) = 172200で used 172200 と同値になります。
free 空きメモリ容量が表示されます。
Unused memory (MemFree and SwapFree in /proc/meminfo)
使われていないメモリ容量です。
shared 共有メモリ容量が表示されます。
Memory used (mostly) by tmpfs (Shmem in /proc/meminfo, available on kernels 2.6.32, displayed as zero if not available)
上記のコマンドは「CentOS7(3.10.0-514.16.1.el7.x86_64)」で実行したものなので、この数値は無視します。
buff/cache カーネルが使用するディスクバッファ容量とキャッシュメモリ容量の合計値表示されます。
Sum of buffers and cache
available
Estimation of how much memory is available for starting new applications, without swapping.
Unlike the data provided by the cache or free fields, this field takes into account page cache and also that not all reclaimable memory slabs will be reclaimed due to items being in use (MemAvailable in /proc/meminfo, available on kernels 3.14, emulated on kernels 2.6.27+, otherwise the same as free)
スワップすることなく、新しいアプリケーションを開始するために使用できるメモリ量の見積もりです。
このフィールドは、キャッシュまたは空きフィールドによって提供されるデータとは異なり、ページキャッシュを考慮し、使用中のアイテムで再利用可能なメモリスラブのすべてを再利用するわけではありません。(MemAvailable in /proc/meminfo、エミュレートされているためカーネル3.14で使用可能です。カーネル2.6.27+、それ以外はフリーと同じ値です)
■Swap
- total スワップに割り当てたディスクサイズです。
- used 割り当てたスワップの中で使用中のサイズ。
- free 割り当てたスワップの中で使用していないサイズ。
※sharedの欄は無視するようにmanコマンドで書かれています。
| 説明 free はシステムの物理メモリとスワップメモリそれぞれに対して、使用量と空き容量を表示し、カーネルが用いているバッファも表示する。 共有メモリの欄は無視してほしい。これは古い機能の名残である。 |
freeのサイズが小さいとメモリ不足が発生している?
たとえば下記のfreeコマンドの結果を見てみましょう。
| # free total used free shared buff/cache available Mem: 500452 172200 15676 28920 312576 260840 Swap: 4194300 126968 4067332 |
freeの値が 15676KB です。
→free の値は 15.6MBです。
一見すると少ないように見えますが、本当にメモリが不足しているのでしょうか?
実は Linuxは、残ったメモリを「バッファ」と「キャッシュ」に利用しています。
そして Linux は稼働し続けると free の値はゼロに近づいていきます。
そのため空きメモリ(free)が少なく見えてしまいますが、実際にメモリが枯渇していると判断できません。
本当にメモリが不足しているかどうかは vmstat コマンドの結果と突き合わせて調査する必要があります。
バッファとは何か?
バッファは I/Oアクセスする時に、直接I/Oに行くのではなく、キャッシュ経由でアクセスさせる為のメモリです。
キャッシュとは何か?
ファイルのデータをメモリに入れておいて、再度アクセスがあった時に素早く返す為の領域です。
1度アクセスがあったファイルは、再度使われる可能性が高いので保持しています。
キャッシュを使うことでI/Oアクセス(データアクセス)を高速化しています。
vmstatコマンド
| # vmstat 1 procs ———–memory————— —swap– —io— —system– ——–cpu——- r b swpd free buff cache si so bi bo in cs us sy id wa st 2 0 126968 19560 0 309952 0 0 1 1 3 12 0 0 100 0 0 0 0 126968 19560 0 309964 0 0 0 0 44 62 0 1 99 0 0 0 0 126968 19560 0 309964 0 0 0 0 51 67 0 0 100 0 0 0 0 126968 19560 0 309964 0 0 0 0 54 66 0 0 100 0 0 0 0 126968 19436 0 309964 0 0 0 0 58 62 0 0 100 0 0 |
■procs プロセスに関する情報が表示されます
r:実行可能なプロセス数、ランタイム待ちのプロセス数(runキュー、ランキュー、run queue とも言われます)
The number of runnable processes (running or waiting for run time). → 英語 man vmstat だと、ランナブルプロセの数となっている。
r 2→実行可能もしくはランタイム待ちのプロセスが2つある。
※日本語 man vmstat だと「ランタイム待ちのプロセス数」のみになっています。
rは実行可能プロセス数、ランタイム待ちのプロセス数で、実行中のプロセスは「CPU」の欄に表示されます。(us,sy,id,wa,st)
b:割り込み不可能なスリープ状態にあるプロセス数(I/O待ちのプロセス数)
The number of processes in uninterruptible sleep.
本来ならば実行できるはずのプロセス数。(ディスクやネットワークからのI/O(入出力)を待っている)
このbの数値が大きい場合はI/Oが原因の可能性があります。
■memory メモリに関する情報が表示されます
swpd:仮想メモリの総量(単位:キロバイト)
the amount of virtual memory used.
上の例では「126968KB」→「126MB」の仮想メモリ。
free:空きメモリの量(単位:キロバイト)
the amount of idle memory.
buff:バッファに使用されているメモリの量(単位:キロバイト/秒)
the amount of memory used as buffers.
cache:キャッシユメモリ容量が表示されます
the amount of memory used as cache.
inact:アクティブでないメモリの量 (-a オプション)
the amount of inactive memory. (-a option)
active: アクティブなメモリの量 (-a オプション)
the amount of active memory. (-a option)
■swap スワップメモリの情報が表示されます
si:ディスクからスワップインされているメモリの量(単位:キロバイト/秒)
Amount of memory swapped in from disk (/s).
so:ディスクにスワップしているメモリの量(単位:キロバイト/秒)
Amount of memory swapped to disk (/s).
※物理メモリが十分に足りていれば「si」「so」の数値はゼロになります。
ここの数値が多いということは物理メモリが不足している可能性があります。
※特にso(スワップアウト)の数値があまりにも多すぎる場合は物理メモリの不足が原因です。
■io ブロックデバイスに関する情報が表示されます
bi:ブロックデバイスから受け取ったブロック(単位:ブロック/秒)
Blocks received from a block device (blocks/s).
※サイトによってはbiとboの記載が逆の場合があります。しかし英語 man vmstat では「received」とあるので受け取ったブロックで正解か。
bo:ブロックデバイスに送られたブロック(単位:ブロック/秒)
Blocks sent to a block device (blocks/s).
■system
システムに関する情報が表示されます
in:1秒あたりの割り込み回数(クロック割り込みを含む)
The number of interrupts per second, including the clock.
cs:1秒あたりのコンテキストスイッチの回数
The number of context switches per second.
■CPU
これらは CPU の総時間に対するパーセンテージです。
us:カーネル以外の実行に使用した時間 (ユーザー時間、nice 時間を含む)
Time spent running non-kernel code. (user time, including nice time)
sy:カーネルの実行に使用した時間 (システム時間)
Time spent running kernel code. (system time)
id:アイドル時間。Linux 2.5.41 以前では、IO 待ち時間を含んでいる
Time spent idle. Prior to Linux 2.5.41, this includes IO-wait time.
wa:I/O 待ち時間。Linux 2.5.41 以前では、0 と表示される
Time spent waiting for IO. Prior to Linux 2.5.41, included in idle.
st:仮想マシンから盗まれた時間。Linux 2.6.11より前では未知
Time stolen from a virtual machine. Prior to Linux 2.6.11, unknown.
特定のプロセスがメモリを消費している。
→psコマンドで探す
CPUの使用率は低いが、スワップアウトが大量に発生している
→メモリ不足→メモリを増やす
メモリを増やさない・増やせない場合
→プログラムの改善
DB系→ディスクの中の膨大なデータの中から特定のデータを探す→ディスクI/Oの発生→SSDの導入など
アプリ系→処理が膨大(科学計算、統計データの算出など)→CPUへの負荷
【参考】プロセスの遷移
プロセスは「生成」されてから処理が行われるまで
- 実行可能
- 実行
- スリープ
状態に変化します。
プロセスが「生成」された後、プロセスは「実行可能状態」になります。
実行可能状態とは CPU で処理が実行される準備が整ったということになります。
CPU が使用可能になると、「実行」されます。具体的には処理(計算など)が行われます。
ディスク I/O が発生したり、ネットワークからのレスポンス待ちになると「スリープ」状態になります。
例えば「ps -eflww」コマンドを実行すると多数のプロセスが表示されますが、ほとんどが「スリープ」状態になっています。
CPU の処理速度は極端に速いため、プロセスが200くらい起動していても、常時 CPU の使用率が「0.1%」くらいであることは珍しくありません。
1 つのプロセスが実行中の時は、1 つの CPU が使用中となります。
実行可能状態の場合は、実際には CPU を使用していないため vmstat では「r」で表示されることになります。
/proc/[PID]/ioでプロセスごとのI/O情報が分かる
下記コマンドでプロセスごとのI/Oの統計情報が分かります。
| # cat /proc/327/io rchar: 231461 wchar: 233617 syscr: 130 syscw: 115 read_bytes: 0 write_bytes: 0 cancelled_write_bytes: 0 |
manコマンドを日本語訳しています。
|
/proc/[pid]/io (since kernel 2.6.20) This file contains I/O statistics for the process, for example:
# cat /proc/3828/io The fields are as follows: rchar: characters read 読み込み文字 wchar: characters written 書き込み文字 このタスクが引き起こした、またはディスクに書き込まれる原因となるバイト数。 syscr: read syscalls 読み込まれたシステムコール 読み込みI / O操作の数、つまりread(2)やpread(2)などのシステムコールの数をカウントしようとします。 syscw: write syscalls 書き込まれたシステムコール 書き込みI / O操作の数、つまりwrite(2)やpwrite(2)などのシステムコールの数をカウントしようとします。 read_bytes: bytes read 読み込みバイト数 write_bytes: bytes written 書き込まれたバイト数
cancelled_write_bytes: ここで大きな不正確さは切り捨てられています。 プロセスが1MBをファイルに書き込んだ後にファイルを削除すると、実際には書き出しは実行されません。 Note: In the current implementation, things are a bit racy on 32-bit systems: if process A reads process B’s /proc/[pid]/io while process B is updating one of these 64-bit counters, process A could see an intermediate result. プロセスAがプロセスBの/ proc / [pid] / ioを読み込み、プロセスBがこれらの64ビットカウンタの1つを更新している場合、プロセスAは32ビットシステム上で 中間結果。 |
CPU 使用率が 100% であるが CPU 待ちプロセスが少ない場合
特定のプロセスがひたすら処理され続けている可能性があります。
仮に複数のプロセスが CPU 待ちしている場合はロードアベレージや vmstat の b 列など数値として表れてきます。
- vmstat の b 列 ← 待ち状態のプロセスの数(b:割り込み不可能なスリープ状態にあるプロセス数(I/O待ちのプロセス数))
データベースサーバー(DBサーバー)の場合は、処理に時間が掛かる SQL 文が実行されている可能性があります。
wait I/O が大きい場合は、 ページングが実行されている可能性もあります。
ページングとは
ページングとは「メモリ」と「ディスク」の間で行なう I/O 処理を言います。
メモリにデータが入り切れない場合にあふれたデータをディスクに退避させたりします。
ページングが多発するとシステムに負荷が掛かり、処理が遅くなります。
CPU 使用率が 0% に近いのに処理が遅い場合
ユーザーからサーバーまでの間で何か遅延する原因がある可能性があります。
ネットワークが原因でサーバーまでリクエストが届いていないか確認します。
プロセスとスレッドの調査(psコマンド等)
ps -eflww コマンド
- -e 全てのプロセスを選択します。-A と同等です。
- -f 完全なフォーマットでリストします。
- -l 長いフォーマットで表示します。
- ww 出力結果が途中で消えません。(1つの w でも途中で消える場合は 2つの ww を付けます)出力幅を広げるオプションで w を 2 つ指定すると、幅の制限がなくなります。
ww を付けると途中で改行されないためお勧めです。
|
[test@SAKURA_VPS ~]$ ps -eflww |
プロセスとスレッドの違い
プロセスとはプログラムがOS上に実態を持ち、実行できる状態になったものを言います。
- プログラム ← ファイル
- プロセス ← プログラムがメモリにロードされて実行できる状態になったもの
スレッドは、プロセスの中での実行単位を意味します。
マルチスレッドのプログラムで、複数 CPU が搭載されているサーバーなら、1プロセスの中の各スレッドが同時実行することができます。
→非常に効率が良くなりますが、反面、同期処理などプログラムの開発が難しくなります。また、CPU やメモリなどリソースを大量に消費します。いわゆる処理のオーバーヘッドが増えます。
■オーバーヘッドとは?
間接的な負荷やコストを言います。
例えば処理のオーバーヘッドとは、各スレッドが同期を取るためにすべてのスレッドの状態をチェックしたり、状態を管理するためのコストなどが考えられます。
まとめ
「スワップアウト」と「ページアウト」の違いは難しいですね。
スワップアウトは「広義的に実メモリからディスクに退避すること」を言います。
ページアウトは「実メモリから仮想メモリにページを退避すること」を言います。
まだまだ Linux カーネル内部について勉強が必要だと感じました。
manコマンド参考
manページの使い分け方法
|
$ man ls LS(1) ユーザーコマンド LS(1) 名前 書式 |
manコマンドの結果を日本語で表示されると読みやすいですが、日本語の場合重要な情報が端折られていることがあります。
そのためmanコマンドの結果を英語で表示させたい時があります。
その場合は以下のコマンドを実行します。
|
$ LANG=C man ls LS(1) User Commands LS(1) NAME SYNOPSIS DESCRIPTION Mandatory arguments to long options are mandatory for short options too. |
英語で表示されます。
参考サイト&図書
以下、参考サイトです。
https://www.manageengine.jp/support/kb/Applications_Manager/?p=1838
また、時間がある時はこの本を読んでインフラの基本を再確認しています。
インフラ系のエンジニアにおすすめのドキュメントです。

![]()
絵で見てわかるOS/ストレージ/ネットワーク~データベースはこう使っている (DB Magazine Selection)![]()



