目次
S3 の特徴
- S3 の評価指数は「可用性」と「耐久性」(数字で評価している)
- 耐久性は 99.999999999% のイレブンナイン
- 可用性は 99.99%
- リージョン内で 3 か所以上のデータセンターにデータを保存してます。
- バケット ← フォルダ
- オブジェクト ← ファイル
- 段階的な価格設定モデルを採用しています。
■可用性と耐久性の違い
- 可用性(availavility)
- 耐久性(durability)
- 可用性は、システムが停止する時間を短くすること。例えば、障害が発生することを前提に冗長構成を組んで一方に障害が発生した場合に自動的にフェイルオーバーを実行してサービス停止の時間を短くするなどです。
- 耐久性は、長く持ちこたえることを言います。例えば、100時間連続稼働が可能なマシンと1,000時間連続稼働が可能なマシンがあった場合は、1,000時間連続稼働が可能なマシンの方が耐久性があります。
- S3 の耐久性はイレブンナイン(99.999999999%)
- 可用性が99.99%ということは、年間 1 時間程度サービスが止まります。しかしデータが消えるわけではありません。
■S3 の評価指標について

S3バケットに保存することができるオブジェクトの最大ファイルサイズ
S3バケットに保存することができるオブジェクトの最大ファイルサイズは 5TB になります。
S3 ストレージクラス
■S3 ストレージクラスの種類
- S3 標準 ← 高頻度アクセスの汎用ストレージ用に使用します。
- S3 Intelligent-Tiering ← 未知のアクセスパターンのデータ、またはアクセスパターンが変化するデータ用に使用します。
- S3 標準–低頻度アクセス(S3 標準-IA、S3 Standard-IA) ← データアクセスが低頻度(余りアクセスされないが即座に取り出したい)の場合に有効です。複数アベイラビリティゾーンに展開されるので重要なデータの長期保存に適しています。
- S3 1 ゾーン-低頻度アクセス(S3 1 ゾーン-IA、S3 One Zone-IA ← 長期間使用するが低頻度アクセスのデータ用、S3 標準–低頻度アクセスより20%低コストで単一アベイラビリティゾーンに保存しています。単一 AZ にデータを保存するのでコストが低いですが、データ冗長性は劣るため、ログファイルなど重要ではなく最悪消失してもいいデータを低価格に保存するのに向いています。
- Amazon S3 Glacier(S3 Glacier)
- Amazon S3 Glacier Deep Archive(S3 Glacier Deep Archive) ← 長期アーカイブおよびデジタル保存用に使用します。
細かい英単語
- IA ← Infrequent Access(頻度ではないアクセス)の略
- Infrequent ← たまの、めったに起きない、まれな の意味
- One Zone ← 単一アベイラビリティゾーンのこと
S3 Standard-IA と S3 One Zone-IA の選択の観点
- S3 Standard-IA ← 複数アベイラビリティゾーンで重要なデータを保存する。
- S3 One Zone-IA ← 単一アベイラビリティゾーンで重要ではないデータを保存してコストを節約する。
S3には低冗長化のオプションもあります。
■Amazon S3 低冗長化ストレージ(S3 RRS)
- Amazon S3 の標準ストレージと比べて、冗長性レベルを下げることで、重要性の低い、再生可能なデータを保存するのに適しています。
- 年次ベースで、99.99% の堅牢性および 99.99% の可用性を提供するよう設計されています。
- 耐久性が低く、AWS で非推奨ストレージとなっています。
- RRS ← Reduced Redundancy Storage の略。低冗長化ストレージ。
■S3 各ストレージクラスの可用性と耐久性
- S3 標準(S3 STANDARD) 可用性99.99% 耐久性99.999999999%
- S3 低冗長化ストレージ(S3 RRS) 可用性99.99% 耐久性99.99%
- S3 標準-IA(S3 Standard-IA) 可用性99.9% 耐久性99.999999999%
- S3 1 ゾーン-IA(S3 One-Zone-IA) 可用性99.5% 耐久性99.999999999%
※意外なことに低冗長化ストレージよりも S3 1 ゾーン-IA の方が可能性が低い為、注意
S3 Glacier
- Glacier ← 氷河の意味。
■S3 Glacier の耐久性
- Amazon S3 Glacier は、アーカイブの平均年間耐久性が 99.999999999% となるように設計されています。
S3 Glacier ボールトロック(Vault Lock)
S3 Glacier に保存されているデータが対象になります。WORM 要件を満たします。ボールトロックとオブジェクトロックは違います。
- S3 Glacier ボールトロックでは、ボールトロックポリシーを使用して S3 Glacier のコンプライアンス管理を簡単にできます。
- ボールトロックポリシーで「write once read many」(WORM) などのコントロールを指定して今後編集できないようにします。
S3 Object Lock(S3 オブジェクトロック)
S3 オブジェクトロックは、Amazon S3 オブジェクトが一定期間または無期限に削除または上書きされるのを防ぐのに役立ちます。オブジェクトロックは、write-once-read-many (WORM) モデルを使用してオブジェクトを保存します。
S3オブジェクトロックの保持モード(リテンションモード)は2つあります。
コンプライアンスモード
コンプライアンスモードでは、AWS アカウント の root ユーザーを含め、ユーザーが、保護されたオブジェクトのバージョンを上書きまたは削除することはできません。つまり、root でも絶対に消せません。
例えば、コンプライアンスでログを7年間保持しなければいけない場合、root でも絶対に削除できないようにするにはコンプライアンスモードを選択します。
ガバナンスモード
コンプライアンスモードよりもゆるいです。ガバナンスモードでは、特別なアクセス許可を持たない限り、ユーザーはオブジェクトのバージョンの上書きや削除、ロック設定を変更することはできません。逆に言えば特別なアクセス許可を与えられた限定された管理者なら削除できます。例外があるということです。
データのアクセス時間
- S3 標準
- S3 Intelligent-Tiering
- S3 標準 IA
- S3 1 ゾーン
- Amazon S3 Glacier ← 数分から数時間までの 3 つのオプション
- Amazon S3 Glacier Deep Archive ← 12 時間から 48 時間までの 2 つのアクセスオプション
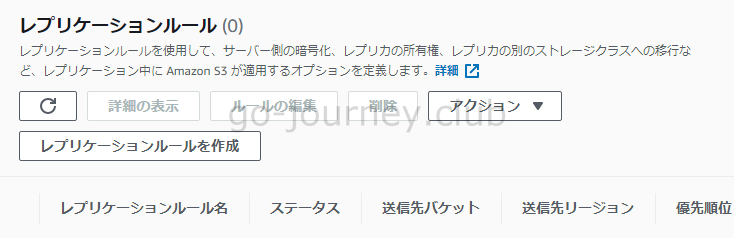
S3 オブジェクトのレプリケーション
そもそも S3 自体が耐久性がイレブンナイン(99.999999999%)で可用性が 99.99% なのでデータが紛失したり壊れたりする心配はないと言ってもいいですが、更にレプリケーションの機能もあります。
- レプリケーションを使用すると、Amazon S3 バケット間でオブジェクトを自動で非同期的にコピーできます。
- オブジェクトのレプリケーションに設定するバケットは、同じ AWS アカウントでも別の AWS アカウントでも設定できます。
- オブジェクトは、単一の送信先バケットまたは複数のレプリケート先バケットにレプリケートできます。
- バケットに対するオブジェクト作成・更新・削除などのデータ処理のイベントをトリガーとしてレプリケーションが実行されます。AWS CLI のコマンドでも手動で実行することが可能です。
■レプリケーションルールの管理画面
S3 バケット命名要件
S3 バケットの命名要件です。
- バケット名は 3 ~ 63 文字の長さで、小文字、数字、ピリオド、ダッシュのみを使用できます。
- バケット名は小文字または数字で始まっている必要があります。
- バケット名では、アンダースコア、末尾のダッシュ、連続するピリオド、隣接するピリオドとダッシュは使用できません。
- バケット名を IP アドレス (198.51.100.24) として書式設定することはできません。
- S3 ではバケットをパブリックにアクセス可能な URL として使用できるので、グローバルに一意なバケット名にする必要があります。
S3 アクセス権限
■S3 へのアクセス権限の設定方法
- 特定のバケットやオブジェクトに対してアクセス権限を設定したい。 ← バケットポリシー
- 特定の IAM ユーザーを視点として、バケットやオブジェクトに対してアクセス権限を設定したい。 ← IAM ポリシー
※バケットポリシーと IAM ポリシーは同じようにアクセス権限が設定できますが、視点というか観点が異なっています。全部バケットポリシーで行く、全部 IAM ポリシーで行くといったような統一化もできますが、逆に管理が大変になると思いますので視点や観点で使い方を分けた方がよいです。
別 AWS アカウントに S3 バケットへのアクセス権を設定する場合
別の AWS アカウントに自分が所有する S3 バケットのアクセスを許可したい場合は、IAM ポリシーとバケットポリシー両方の許可設定が必要となります。
- IAM ポリシー
- バケットポリシー
バケットポリシーは ARN(Amazon Resource Name)で AWS アカウント指定をすることが可能です。どちらのポリシーも許可してないとアクセスは拒否されます。
ポリシー例
リクエストヘッダーに暗号化指定がない場合に拒否する
Deny ステートメントで、”Condition”: {“Null”: {“s3:x-amz-server-side-encryption”: “true”}} を指定します。Null 条件演算子を使用して、リクエストヘッダーに暗号化指定があるかどうか確認します。Null の場合は Deny(拒否)します。
s3:GetObject
s3:GetObjectの許可で S3 バケット内のオブジェクトの読込処理のみが許可されます。この設定を利用して静的 WEB ホスティングが可能となります。
Bucket Owner Enforced(バケット所有者の強制)
S3 の Bucket Owner Enforced は、S3 Object Ownership の設定の1つで、これを有効にすると ACL を無効化し、そのバケットに入る全オブジェクトの所有者を常にバケット所有者に統一する仕組みです。現在の一般的な S3 運用ではこの設定を使って ACL を無効化することを推奨しています。新規バケットではこれがデフォルトです。
分かりやすく言うと、昔の S3 は「バケットを持っている人」と「オブジェクトをアップロードした人」が別アカウントだと、アップロードした側がそのオブジェクトの所有者になることがありました。そのため、バケット管理者なのにオブジェクト権限を自由に扱えない、というややこしさがありました。Bucket Owner Enforced にすると、誰がアップロードしても最終的な所有者はバケット所有者になるので、この問題を避けられます。
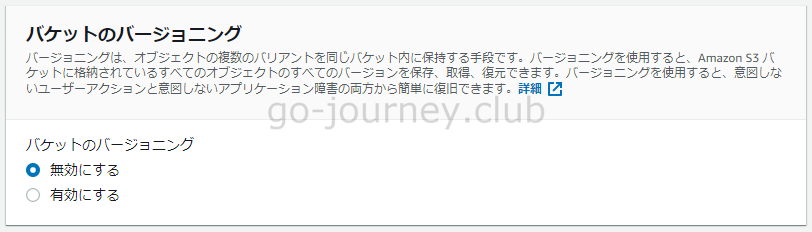
データのバージョニング
■オブジェクトデータのバージョニング
- Amazon S3 バージョニングを使用すると、1 つのバケットで複数バージョンのオブジェクトを維持できます。
- 複数バージョンのオブジェクトを 1 つのバケットに保存できます。
- S3 バージョニング は、意図しない上書きや削除の結果からユーザーを保護します。
S3の暗号化
データを保護するために S3 にかかわる処理に対してデータを暗号化することができます。
データ保護とは、
①データが移動中(Amazon S3との間で移動するとき)および
②静⽌しているとき(Amazon S3データセンターのディスクに保存されている間)
にデータを保護することを指します。
Secure Sockets Layer(SSL)またはクライアント側の暗号化を使⽤して、転送中のデータを保護できます。
Amazon S3の保存データを保護するための次のオプションがあります。
- サーバー側の暗号化 – データセンターのディスクに保存する前にオブジェクトを暗号化するようAmazon S3に要求し、オブジェクトをダウンロードするときにオブジェクトを復号化します。
- クライアント側の暗号化 – クライアント側でデータを暗号化し、暗号化されたデータをAmazon S3にアップロードします。この場合、暗号化プロセス、暗号化キー、および関連ツールを管理します。
以下の画像のように「サーバー側の暗号化」で「有効にする」にチェックを入れるだけで簡単に暗号化ができます。
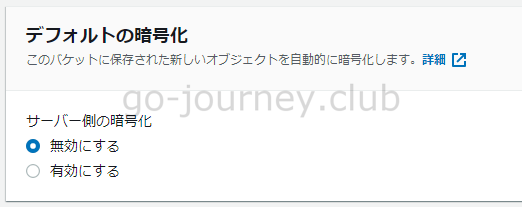
S3 のデータを暗号化できます。
サーバーサイド暗号化を使用すると、
- オブジェクト(ファイル)を保存する前に暗号化し、
- オブジェクトをダウンロードするときに S3 側で自動で復号します。
そのためユーザー側で暗号化/復号をする必要はありません。
■暗号化方式
S3 は KMS を利用した暗号化と、S3 独自の暗号化のどちらかを選択できます。
AWS KMSを利用して暗号化した場合は、AWS KMSキーを復号するための権限が必要となります。
S3 内で管理されるキーを用いてデータを暗号化する場合は KMS は利用できません。
CSE(Client Side Encryption)
クライアントサイド暗号化。サーバサイドで利用できません。ユーザーが独自の暗号化キーを利用して暗号化したオブジェクトを S3 に保存して、暗号化キーの生成・管理はクライアントで実行する形式です。
SSE-S3(Server Side Encryption)
S3 で管理された暗号化キーにより実施されるサーバーサイド暗号化です。ユーザーがキーに対するアクセス管理はできませんが、署名バージョン4 によりアクセス制限が設定され、所有者であるAWSアカウント ID 以外からのアクセスを拒否します。暗号化と復号化を S3 が自動で実施してくれるため管理に手間がかかりません。
SSE-KMS
SSE-KMS は、Server-Side Encryption with AWS Key Management Service の略です。Server-Side Encryption は、サーバー側暗号化です。SSE-S3 と異なりユーザーが KMS 上でのキー作成と管理を実施する必要があります。
例えば、S3 にファイルをアップロードした場合、S3 が KMS のカギを使って暗号化します。S3 が KMS のカギを使って暗号化します。ユーザー側が自分で暗号化のプログラムを作る必要はなく AWS が裏側で暗号化・復号をやってくれます。
SSE-C
ユーザが管理する鍵により暗号化をします。これにより、S3上に置かれたコンテンツを柔軟に保護できるようになります。ユーザーが独自の暗号化キーを設定できます。
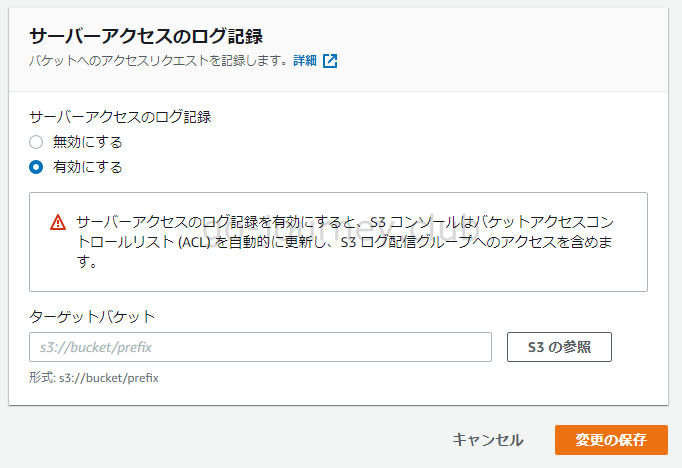
S3 サーバーアクセスログ(S3 Server Access Logging)
S3 サーバーアクセスログを取得することが出来ます。
S3 サーバーアクセスログの有効化
S3 はサーバーアクセスログを記録することができます。バケットへのアクセスログではなくサーバーアクセスログと記載があるのはなぜでしょうか?
サーバーアクセスログを「有効にする」に設定すると、サーバーアクセスログが取得されるようになりますが、S3 の暗号化を有効にしていると自動的にサーバーアクセスログも暗号化されます。
S3の料金
■S3 の料金が決定する要素
- 選択したストレージクラス(S3 標準、S3 Intelligent-Tiering 等のストレージクラス。Glacierを選択すると安くなる。)
- 保存したデータの容量(GB)
- データ転送量
- リクエスト数
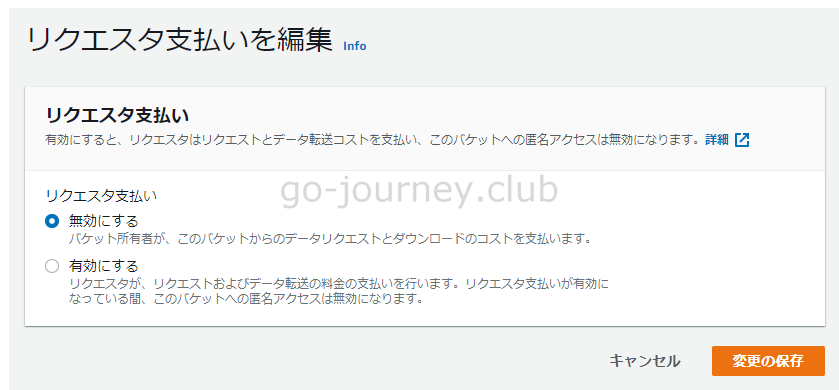
S3 の利用料金を使用者に支払わせることができる
基本的に Amazon S3 のコストはバケット所有者が負担しますが、バケットをリクエスタ支払いバケットとして設定すると、リクエスト及びバケットからのデータのダウンロードにかかるコストは所有者ではなくリクエストしたリクエスタが支払います。
S3 バケットを作成後に「プロパティ」タブをクリックするとリクエスタ支払いを設定できます。
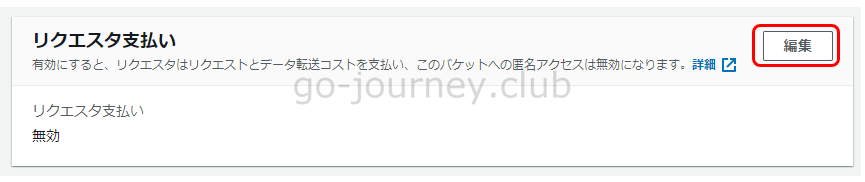
有効にするとリクエスタがリクエスト及びデータ転送の料金の支払いをすることになります。