SQLクエリをまとめました。SQLクエリを書いて実行する環境ですが、普段は VSCode を利用しています。VSCode が一番慣れていて使い勝手がいいです。Workbench や DBeaver や Manegement Studio などがありますが、 VSCode が利用できるなら利用しています。拡張機能があるのもよいですね。Cursor もありますが結局 VSCode に戻ってきます。
ちなみに VSCode の拡張機能は「MySQL Shell for VSCode」がお勧めです。インターフェイスは以下のような感じです。
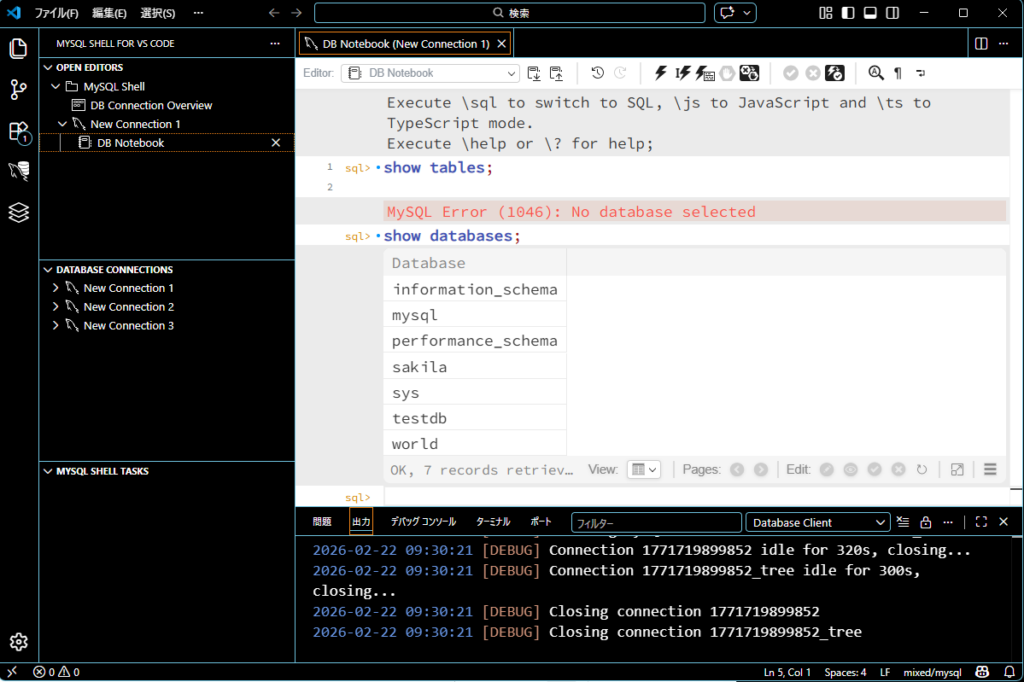
気に入っている点は、下図のようにクエリを実行した結果セットを上に残したまま次のクエリを新たに実行できる点です。これって意外と役に立ちます。テーブルの比較や複数のテーブルをパッと見てテーブル間の構成を確認する場合など。
目次
基本まとめ
SQL クエリの基本をざっくりとまとめます。
DDL(Data Definition Language)(データ定義言語)
構造を定義・変更する SQL です。
- CREATE DATABASE
- CREATE TABLE
- ALTER TABLE(列追加・型変更など)
- DROP TABLE
DML(Data Manipulation Language)(データ操作言語)
データ(行)を検索・追加・更新・削除する SQL です。
- SELECT
- INSERT
- UPDATE
- DELETE
DCL(Data Control Language)(データ制御言語)
権限(アクセス制御)を管理する SQL です。
- GRANT
- REVOKE
MySQL
先頭から n 行取得する
MySQLの場合は LIMIT 句を加えます。
SELECT
*
FROM
商品マスタ
ORDER BY
卸単価 DESC
LIMIT 5
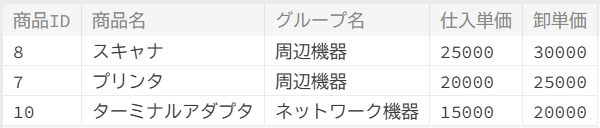
; n 行目から m 行目まで取得する
(例)6行目から8行目まで取得する。
0から始まるので6行目は5になります。そこから3行取得するので LIMIT 5,3 になります。
SELECT
*
FROM
商品マスタ
ORDER BY
卸単価 DESC
LIMIT 5,3
;
元のテーブル
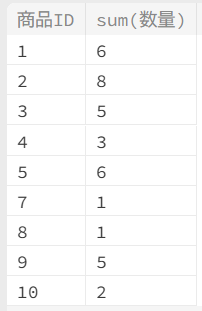
売上数量の合計値を出す
select
商品ID,
sum(数量)
FROM
売上データ
group BY
商品ID
;結果セット
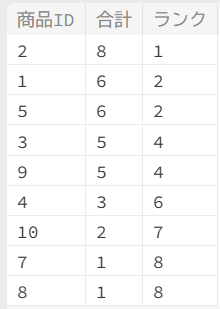
合計の売上数量にランキングを付ける
select
商品ID,
sum(数量) as 合計,
rank() over(order by sum(数量) desc) ランク
from
売上データ
group BY
商品ID
order by 合計 desc
;
最大値を持つレコードの商品IDと最大値を取得する
まずは、最大値だけ取得します。
SELECT
MAX(卸単価)
FROM
商品マスタ
;
これで最大値が分かるので、ここからサブクエリを作ります。
SELECT
商品ID,
商品名,
卸単価
FROM
商品マスタ
WHERE
卸単価 =
(
SELECT
MAX(卸単価)
FROM
商品マスタ
)
;
テーブル名を変更する
シンプルにテーブル名を変更するだけです。FOREIGN KEY 制約がある場合などは新テーブルに合わせたものを作り直す必要があるので注意です。
RENAME TABLE
顧客マスタ TO 得意先マスタ
;
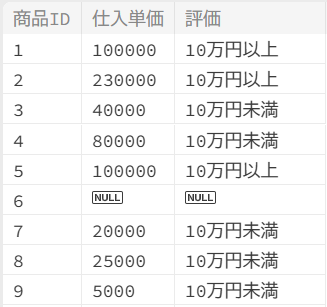
範囲指定する(CASE式)
仕入単価の列で10万円以上か10万円未満か評価します。
SELECT
商品ID,
仕入単価,
CASE
WHEN 仕入単価 >= 100000 THEN "10万円以上"
WHEN 仕入単価 < 100000 THEN "10万円未満"
ELSE NULL
END AS 評価
FROM
商品マスタ
;
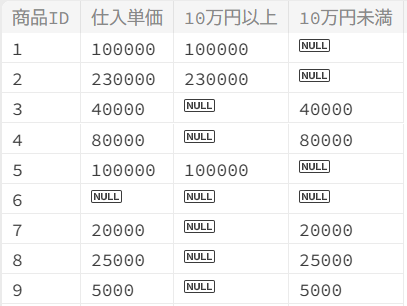
範囲を指定して列を分ける(CASE式)
10万円以上の列と10万円未満の列を分けます。
SELECT
商品ID,
仕入単価,
CASE
WHEN 仕入単価 >= 100000 THEN 仕入単価
ELSE NULL
END AS 10万円以上,
CASE
WHEN 仕入単価 < 100000 THEN 仕入単価
ELSE NULL
END AS 10万円未満
FROM
商品マスタ
;
文字列の「’」をエスケープする
SELECT 'テ''スト'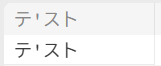
テーブルを作成する(参照整合性、外部キー制約)
- 親テーブル(部署テーブルなど)
- 子テーブル(社員テーブルなど)← 参照する子テーブルに設定する。
参照整合性は子テーブルに設定します。子テーブルが親テーブルを見に行く時に存在しないデータを持つことや不整合を起こさないために制約が必要なためです。
親テーブル
CREATE TABLE Departments
(
dep_name CHAR(32),
CONSTRAINT pk_Departments PRIMARY KEY (dep_name)
);子テーブル
CREATE TABLE employees
(
emp CHAR(32),
age INTEGER,
department CHAR(32),
PRIMARY KEY (emp), -- 主キー設定
-- 外部キー定義(department は親テーブルの Departments.dep_name を参照する)
FOREIGN KEY (department) REFERENCES departments(dep_name)
ON DELETE CASCADE -- 親が消えたら子も消える。
ON UPDATE CASCADE -- 親が更新されたら子も更新される。
);データを挿入する
1行挿入する。
INSERT INTO テーブル名
(列1, 列2, 列3)
VALUES
(値1, '値2', 値3)
;複数行挿入する。
INSERT INTO テーブル名
(列1, 列2, 列3)
VALUES
(値1, '値2', 値3),
(値1, '値2', 値3),
(値1, '値2', 値3)
;テーブルを削除する(DROP)
DROP TABLE テーブル名;MySQL管理系クエリ
データベースのバージョンを表示する
SELECT VERSION();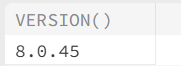
テーブル一覧を表示する
SHOW TABLES;
列情報を取得する
DESCRIBE 商品マスタ;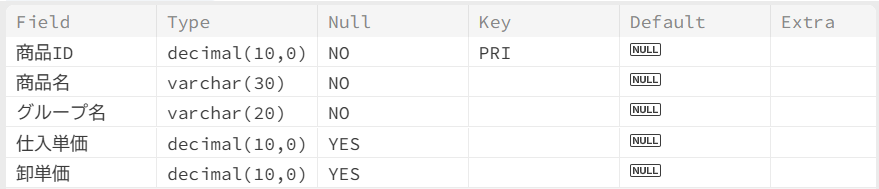
インデックス情報を取得する
SHOW INDEX FROM 商品マスタ;
コメント