いろいろなアプローチをしましたが、なかなかうまく行かなくて悩みましたが最終的にうまく行ったので記事として残します。
(この方法がベストかどうかは不明)
目次
そもそも検索で引っ掛からない特殊文字?
プログラムで様々なドキュメントや文字を読み込んでいると、たまに訳のわからない文字に遭遇することがあります。
それが「©、¢、£」などの特殊文字や「制御文字」です。
- ©、¢、£ ← HTMLの特殊文字
最初のアプローチは、文字列を16進数にダンプする方法
例えば、以下の文字列があったとします。
|
(pyenv) [test@SAKURA_VPS scraping]$ cat code_test.txt |
最初のアプローチは「codecs.encode(var.encode(‘utf-8’), ‘hex_codec’)」を試しました。
【例】
|
var001 = ‘スキルを身に付けるc‘ code01 = codecs.encode(var001.encode(‘utf-8’), ‘hex_codec’) |
これは何をしているのかというと、「スキルを身に付けるc」を16進数に変換して「code01」に代入しています。
以下の処理を考えました。
- 「スキルを身に付けるc」の文字列を「codecs」で16進文字列に変換する
- 16進文字列に変換した文字列を str 型に変換する
- str 型に変換した文字列を sub で特殊文字のコードを指定して削除する
- 16進文字列 から str 型に変換され特殊文字のコードを削除された文字列を str 型文字列に変換する
自分でも処理を書いていて相当無理があるなと思いますが、このアプローチは見事失敗しました。
素晴らしいアイデアを発見
これは Python 素人にとっては難しいなと思っていましたが、素晴らしいアイデアを見つけました。
【参考サイト】
文字→ascii。ascii→文字 ord, chr
https://python.civic-apps.com/char-ord/
ordとは?
ord はアスキーコードを取得する関数です。(つまり文字列をアスキーコードにする関数)
アスキーコードとは、「文字」と「その文字に割り当てられた番号」の対応表のことを言います。
【例】
ASCII文字コード
http://e-words.jp/w/ASCII.html#Section_ASCII%E6%96%87%E5%AD%97%E3%82%B3%E3%83%BC%E3%83%89
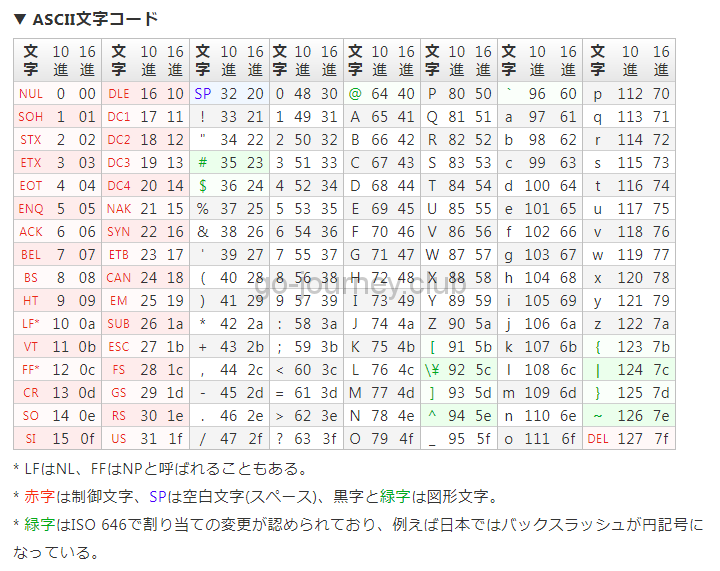
ord はビルトイン関数(組み込み関数)です。
Python 3.6.3 の公式ドキュメントでは
https://docs.python.org/ja/3/library/functions.html
1 文字の Unicode 文字を表す文字列に対し、その文字の Unicode コードポイントを表す整数を返します。例えば、 ord(‘a’) は整数 97 を返し、 ord(‘€’) (ユーロ記号) は 8364 を返します。これは chr() の逆です。
と説明があります。
確かに上の ASCII コード表を確認すると、「a」は「97」です。
しかし ASCII コード表には「127」までしかありません。
「8364」はどこから出てきたのかというと、Unicode のコード表から出てきたようです。
【参考】
http://www.hipenpal.com/tool/characters_to_unicode_charts_in_japanese.php?unicode=69
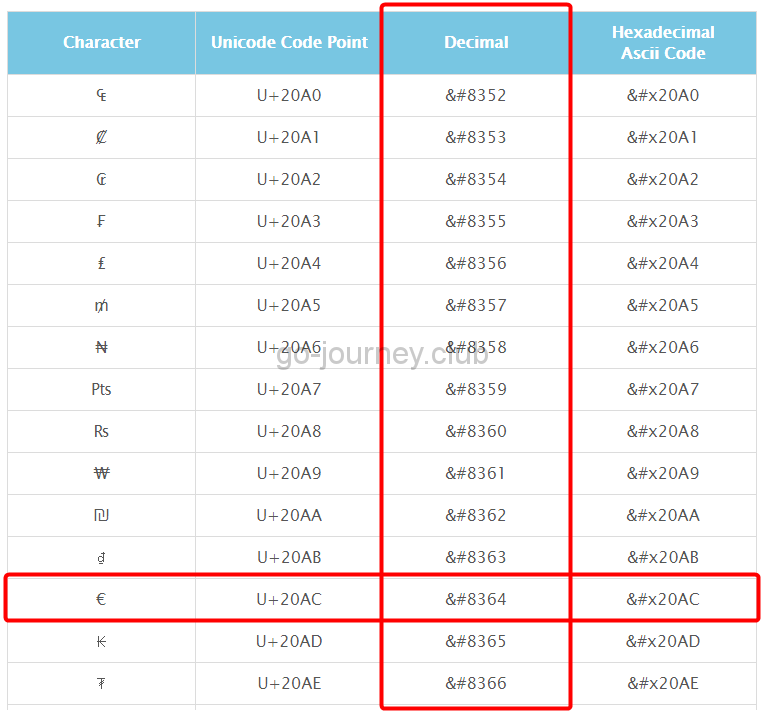
確かに「€」は Unicode 表の「Decimal」の「8364」にありました。
- decimal ← 10進数という意味です。
- Hexadecimal Ascii Code ← Hexadecimal は「16進数」という意味です。16進数の ASCII コードという意味です。
- Unicode Code Point ← 各文字の頭に「U+」が付いているが、これが「コードポイント」です。
特殊文字を削除するプログラム
上記サイトを参考にして ord でアスキーコードに変換し、特殊文字を見つけたら削除する方法です。
|
# -*- coding: utf-8 -*- import re f = open(‘code_test.txt’, ‘r’) for line in lines: # 初期化する # 文字列を1文字ずつ読み込み処理をする # 特殊記号削除後の文字列 # ファイルを閉じる |
プログラムを実行すると以下のようになります。
|
(pyenv) [test@SAKURA_VPS scraping]$ python test.py 116 (pyenv) [test@SAKURA_VPS scraping]$ |
まとめ
文字コードは奥が深いです。
更なる勉強が必要です。
「UTF-8」や「Unicode」など普段の業務では全く意識をしないのですが、プログラムを作成する場合は、更に深くまで知らないと思うようなプログラムを開発できないですね。





コメント