AWS Glue Crawler のロールとポリシーの設計について解説します。
【AWS】RDSのSnapshotをS3バケットにエクスポートする方法

【AWS】Glue Job のロールとポリシーの設計

目次
そもそも Glue 関連のサービスで IAM ロールの設定と IAM ポリシーの設定をしなければいけないものは何か?
Glue 関連のサービスと言ってもたくさんありますが、そもそもGlue 関連のサービスで IAM ロールの設定と IAM ポリシーの設定をしなければいけないものは何でしょうか?
考え方ですが、IAM ロールは Glue ジョブや Glue Crawler のように S3 や RDS や Redshift など他の AWS リソースへアクセスする可能性があるサービスに設定します。(設定できます)
一方で、Glue データカタログなどのテーブル情報などのメタデータを保存するようなサービスには設定できません。(保存するだけで自分からは他にサービスに対してアクションすることがないから)
例えば、その他に IAM ロールを指定可能な Glue 関連サービスとしては以下のようなものがあります。
■Glue Interactive Session
- Glue Studio からジョブ作成時に指定可能な Jyptter Notebook を利用したインタラクティブな開発ノートブック
■Glue DataBrew
- Project
- Job (ProfileJob/RecipeJob)
■参考サイト
AWS Glue インタラクティブセッションの概要
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/interactive-sessions-overview.html
Creating and using AWS Glue DataBrew projects
https://docs.aws.amazon.com/ja_jp/databrew/latest/dg/projects.html
Creating, running, and scheduling AWS Glue DataBrew jobs
https://docs.aws.amazon.com/ja_jp/databrew/latest/dg/jobs.html
AWS Glue について
まずはそもそも Glue とは何をしているのでしょうか。
ETL と言うと分かりやすいですが、Glue だけだと分かりにくいですよね。
AWS Blackbelt に分かりやすい構成図と説明があります。
[AWS Black Belt Online Seminar] AWS Glue
https://d1.awsstatic.com/webinars/jp/pdf/services/20190806_AWS-BlackBelt_Glue.pdf
全体の処理の流れ
Glueが中心となってデータソースからターゲットへデータをETL処理を実施して移行するといったイメージです。
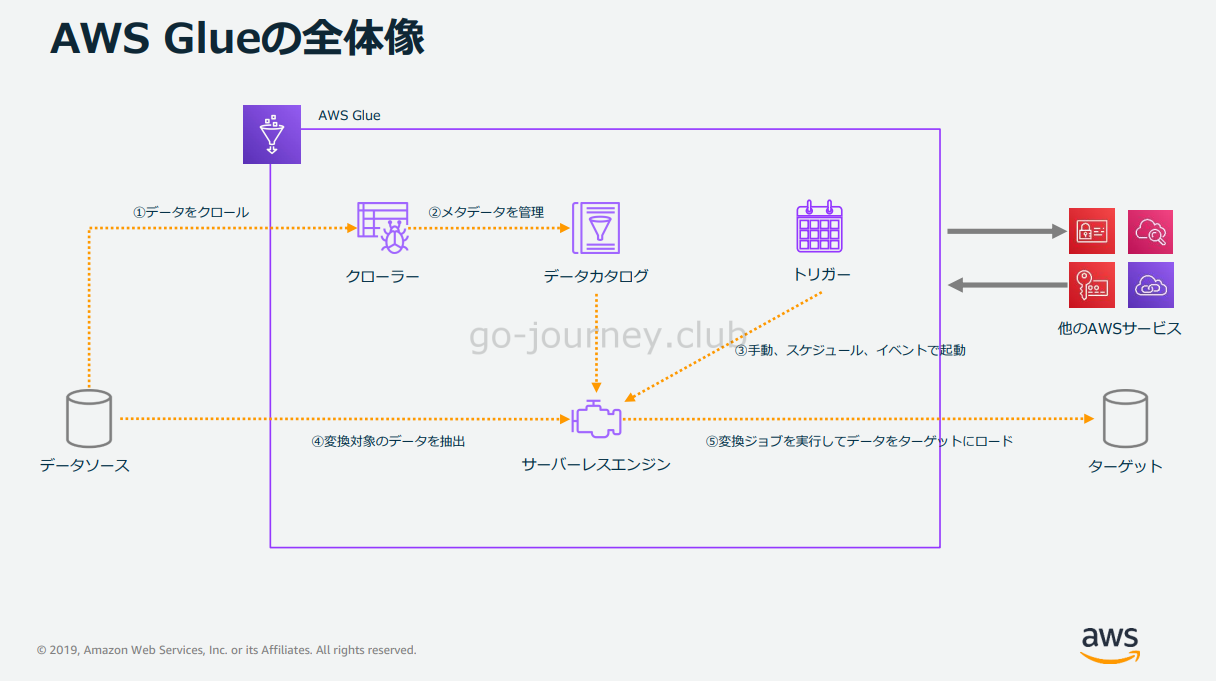
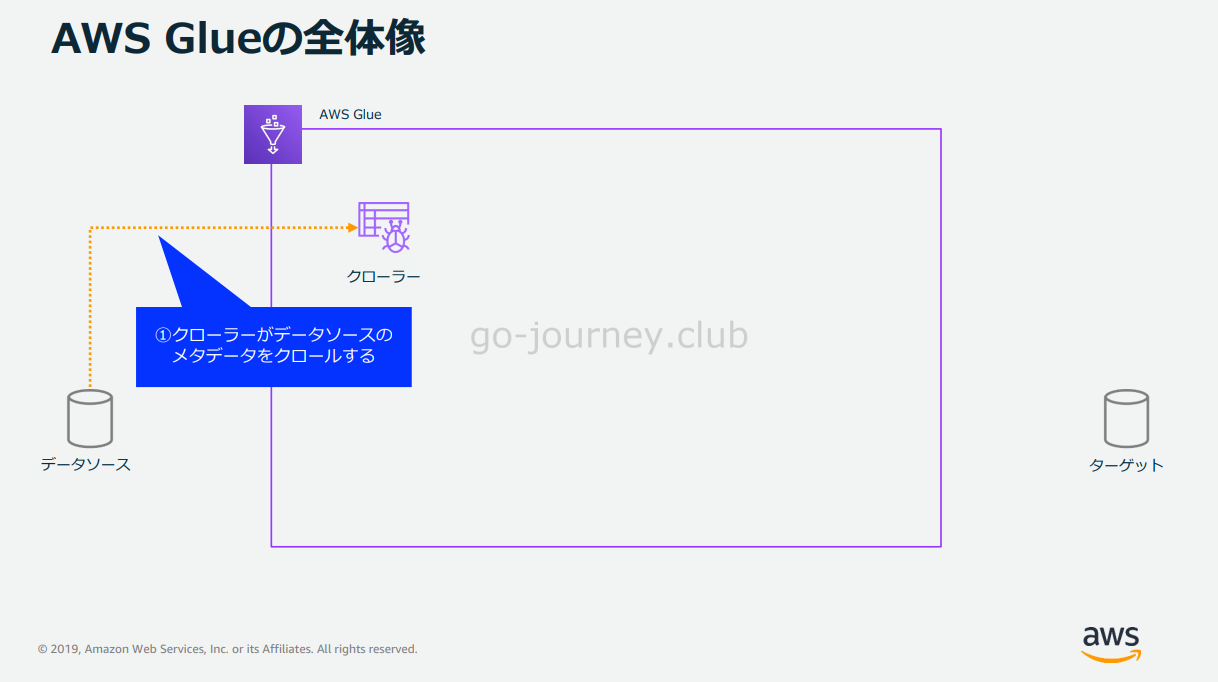
Glue Crawlerの処理の流れ
次に Glue Crawler の処理の流れです。
Crawler(クローラー)がデータソースのメタデータをクロールします。
AWS Glue の概念
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/components-key-concepts.html#components-data-store
- データストア ← データを永続的に保存するリポジトリです。例として S3、RDS などがあります。
- データソース ← プロセスまたは変換への入力として使用されるデータストアです。
- データターゲット ← プロセスまたは変換の書込み先であるデータストアです。
Glue の入力で使用される S3 などのデータストアをデータソースと言います。
Crawler(クローラー)がデータカタログに登録・更新し、メタデータを管理します。
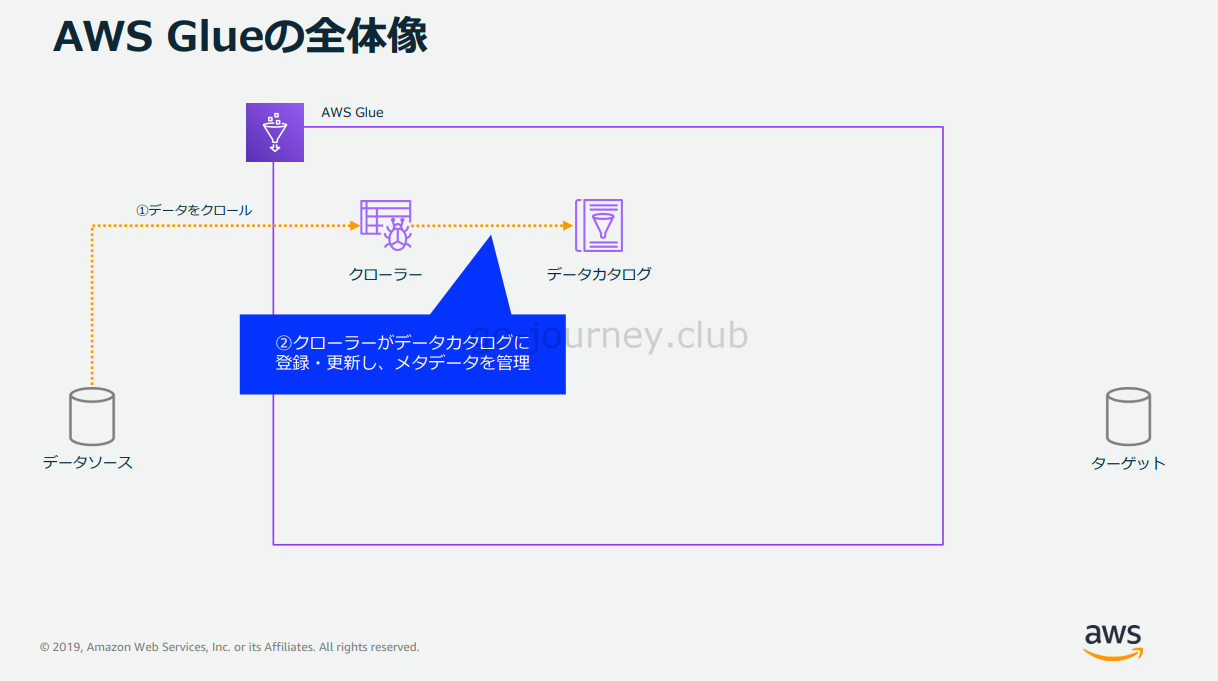
Glue Crawler はデータソースのメタデータをクロールしてデータカタログに登録したり更新したりしてメタデータを管理をするという処理を実行します。難しそうに見えますがやっていることはシンプルですね。
クローラー(Glue Crawler)
Glue Crawler は Glue Data Catalog にメタデータを作成します。

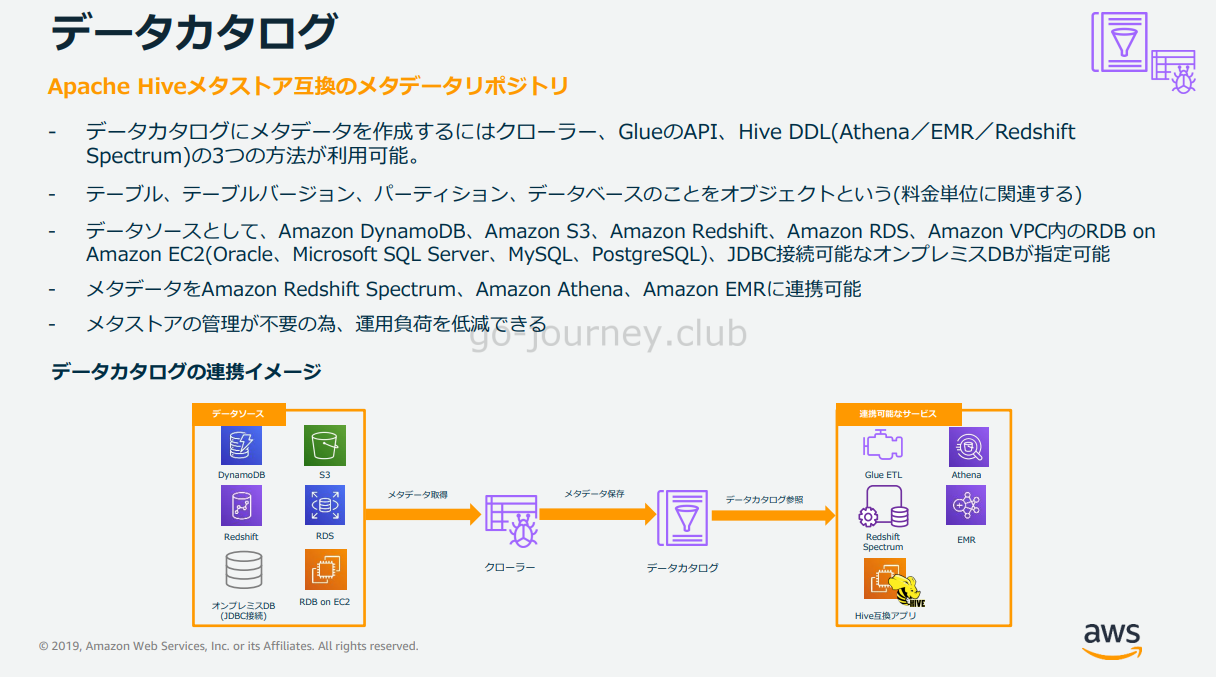
データカタログ(Glue Data Catalog)
AWS Glue の持続的なメタデータストアです。
これには、AWS Glue 環境を管理するためのテーブル定義、ジョブ定義、およびその他のコントロール情報が含まれています。
各 AWS アカウントには、リージョンごとに 1 つの AWS Glue Data Catalog があります。
Glue Crawler の構成図と設計
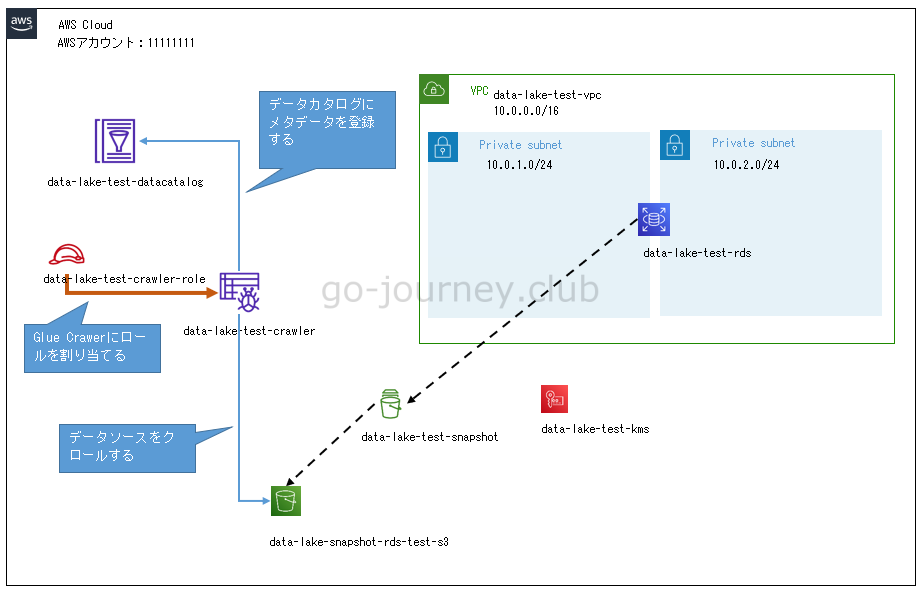
Glue Crawler の構成図です。
データソースは S3(data-lake-snapshot-rds-test-s3)です。
RDS のスナップショットを S3 にエクスポートしています。
【AWS】RDSのSnapshotをS3バケットにエクスポートする方法
■構成図
設計
- RDSのスナップショットをS3バケットにエクスポートしている。
- S3バケットをデータソースとする。
- Glue Crawler(data-lake-test-crawler)がデータソースをクロールする。
- クロールしたメタデータをデータカタログ(data-lake-test-datacatalog)に登録する。
- IAMロール(data-lake-test-crawler-role)を作成し Glue Crawler に割り当てる。
- IAMロール(data-lake-test-crawler-role)には Glue Crawler を実行する権限、データソースの S3 バケットにアクセスする権限、KMS キーにアクセスする権限を割り当てる。
IAMロール、IAMポリシーの作成
具体的に IAM ロール、IAM ポリシーを作成します。
■信頼ポリシー
|
{ |
まずは IAMロール(data-lake-test-crawler-role)に割り当てる信頼ポリシーです。
Glue Crawler に権限を委譲するので「glue.amazonaws.com」を付与します。
■AWSGlueServiceRole(マネジメントポリシー)
|
{ |
次に Glue Crawler を実行するのでマネージドポリシーである「AWSGlueServiceRole」を割り当てます。
名前は Role で終わってますがポリシーです。
権限を確認すると”glue:*”と Glue 全体の権限が割り当てられていて、且つリソースも「*」になっています。
そのため、もっと絞れます。絞るとしたら権限で絞るよりプロジェクトごとにリソースで絞った方が管理しやすいかと思います。
S3 バケットへの権限
■data-lake-test-crawler-role-s3-policy
|
{ |
次にデータソースの S3 バケットへアクセスするためのポリシーを作成します。
Glue Crawler がデータソースをクロールするので S3 への権限(クロールするだけなので”s3:GetObject”があればOK)が必要です。
クローラーの前提条件
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/crawler-prereqs.html
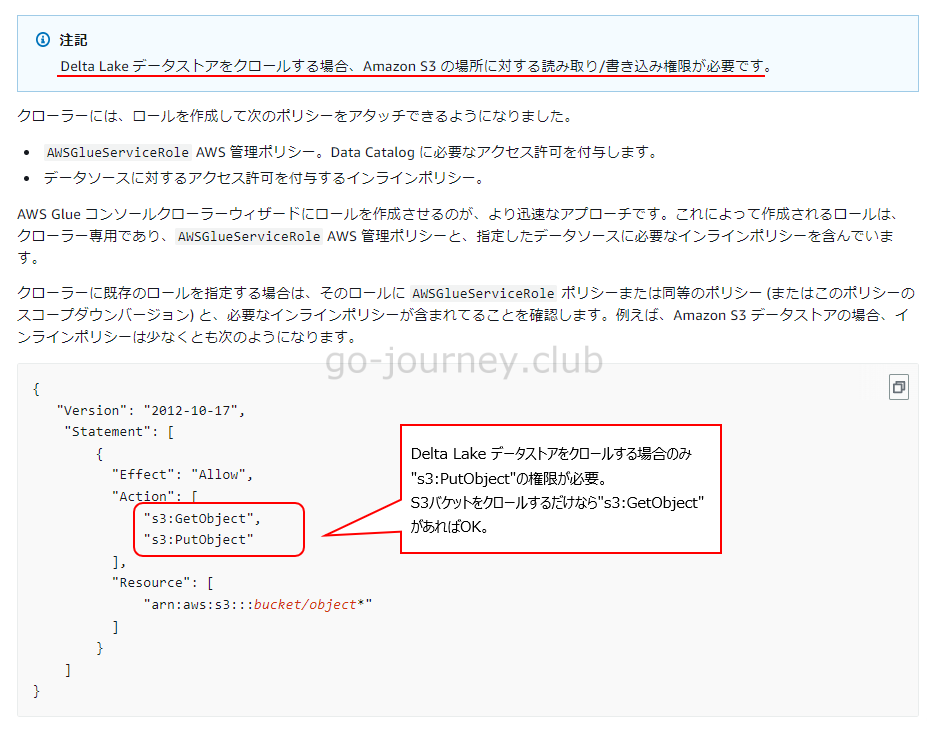
AWS の公式サイトを確認すると「s3:PutObject」も割り当てられていますが、Delta Lake データストアをクロールする場合のみです。
S3バケットをクロールするだけなら”s3:GetObject”があればOKです。
List権限は必要か?
List権限まで必要かどうかは Glue Crawler の設定次第になりそうです。
Crawler のデータソースを S3 として、S3 のパスに S3 バケットもしくはフォルダを指定する場合、内部に含まれるファイルを検索するために s3:ListBucket の権限が必要となります。
ただし S3 パスに特定ファイルのパスを指定し、単一ファイルのみをクロールする場合には、s3:ListBucket の権限は必要となりません。
JDBC 接続の場合は?
JDBC 接続の DB へのクロールについては別途 S3 へのアクション許可は不要です。
KMS キーへの権限
■data-lake-test-crawler-role-kms-policy
|
{ |
KMS で暗号化された S3 のデータソースにアクセスをするので、Glue Crawler に、KMS キーで暗号化したデータを復号するための権限を付与します。
以下の AWS 公式サイトに記載があります。
ステップ 2: AWS Glue 用の IAM ロールを作成する
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/create-an-iam-role.html
SSE-KMS で暗号化された Amazon S3 のソースとターゲットにアクセスする予定がある場合は、AWS Glue のクローラ、ジョブ、開発エンドポイントに、データを復号化するためのポリシーをアタッチしてください。詳細については、「Protecting Data Using Server-Side Encryption with AWS KMS-Managed Keys (SSE-KMS)」を参照してください。
次に例を示します。
{
"Version":"2012-10-17",
"Statement":[
{
"Effect":"Allow",
"Action":[
"kms:Decrypt"
],
"Resource":[
"arn:aws:kms:*:account-id-without-hyphens:key/key-id"
]
}
]
}
以上が Glue Crawler の IAM 権限周りの設計と設定となります。



