AWS Glue Job のロールとポリシーの設計について解説します。
以前、以下の記事を作成したので参考に指定ください。
【AWS】RDSのSnapshotをS3バケットにエクスポートする方法
AWSインフラ研究所
https://go-journey.club/archives/17305
AWSを中心としたクラウドインフラ技術サイト
【AWS】Glue Crawler のロールとポリシーの設計
AWSインフラ研究所
https://go-journey.club/archives/17310
AWSを中心としたクラウドインフラ技術サイト
そもそも Glue 関連のサービスで IAM ロールの設定と IAM ポリシーの設定をしなければいけないものは何か?
Glue 関連のサービスと言ってもたくさんありますが、そもそもGlue 関連のサービスで IAM ロールの設定と IAM ポリシーの設定をしなければいけないものは何でしょうか?
考え方ですが、IAM ロールは Glue ジョブや Glue Crawler のように S3 や RDS や Redshift など他の AWS リソースへアクセスする可能性があるサービスに設定します。(設定できます)
一方で、Glue データカタログなどのテーブル情報などのメタデータを保存するようなサービスには設定できません。(保存するだけで自分からは他にサービスに対してアクションすることがないから)
例えば、その他に IAM ロールを指定可能な Glue 関連サービスとしては以下のようなものがあります。
■Glue Interactive Session
- Glue Studio からジョブ作成時に指定可能な Jyptter Notebook を利用したインタラクティブな開発ノートブック
■Glue DataBrew
- Project
- Job (ProfileJob/RecipeJob)
■参考サイト
AWS Glue インタラクティブセッションの概要
https://docs.aws.amazon.com/ja_jp/glue/latest/dg/interactive-sessions-overview.html
Creating and using AWS Glue DataBrew projects
https://docs.aws.amazon.com/ja_jp/databrew/latest/dg/projects.html
Creating, running, and scheduling AWS Glue DataBrew jobs
https://docs.aws.amazon.com/ja_jp/databrew/latest/dg/jobs.html
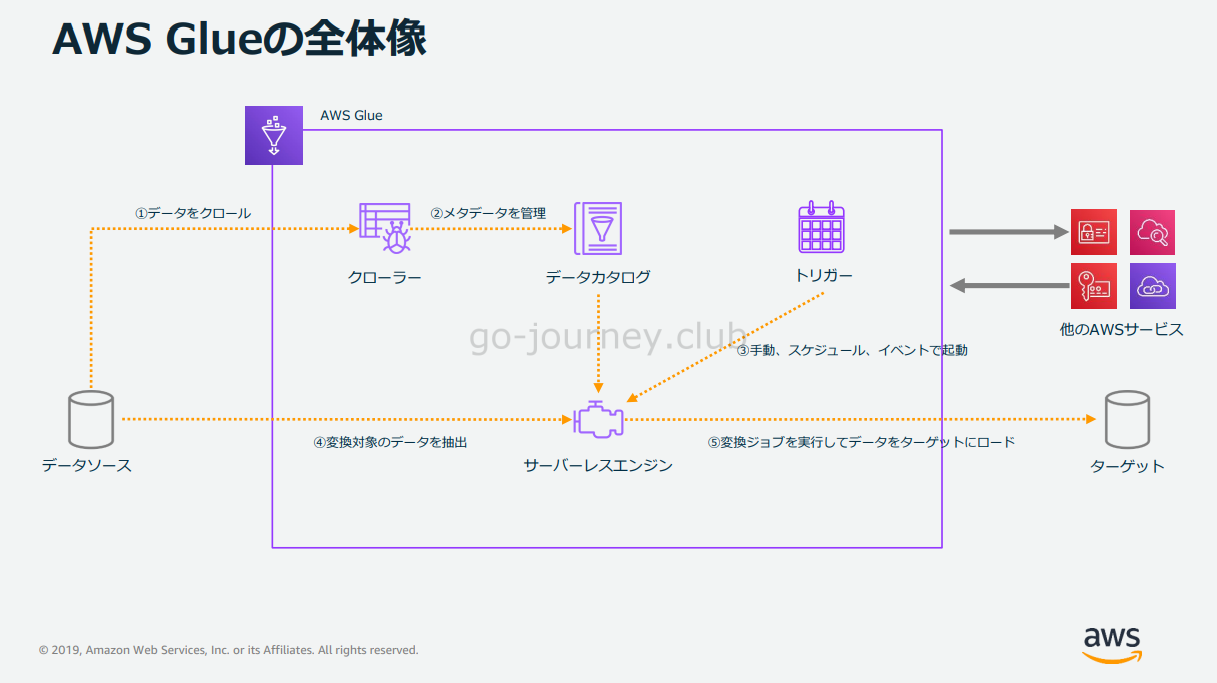
AWS Glue 全体の構成図
最初に AWS Glue の全体の構成図です。
実際にデータソースからデータを抽出しターゲットに出力するのがジョブの役割です。

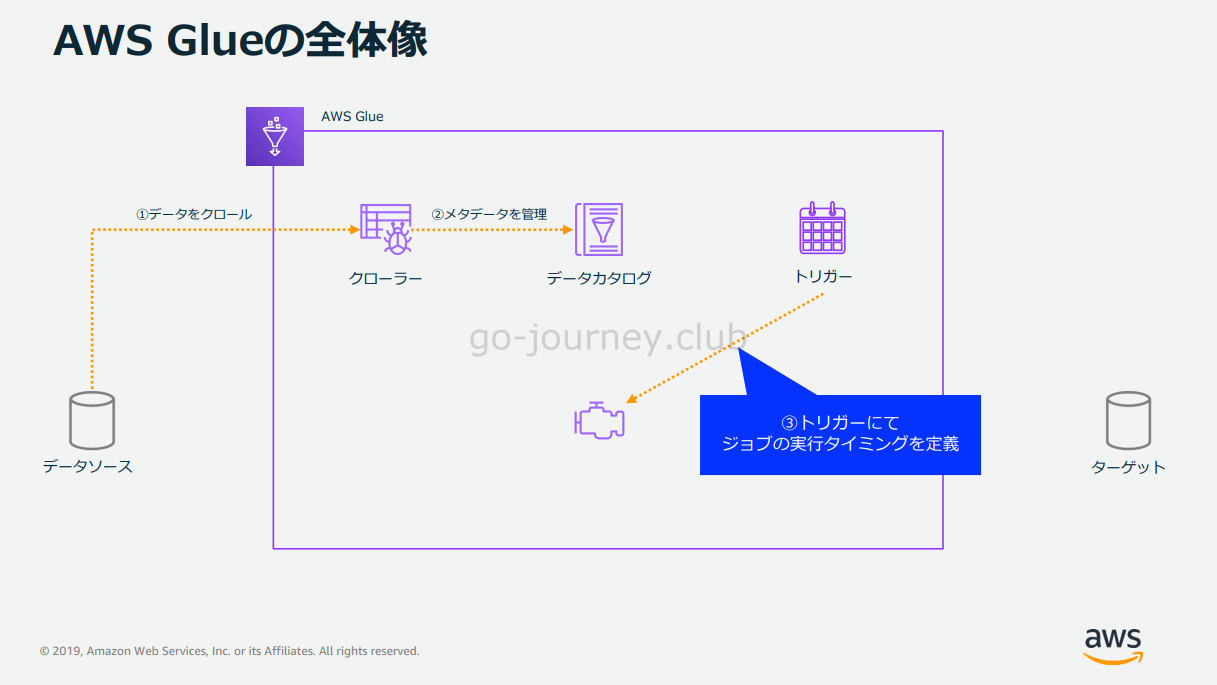
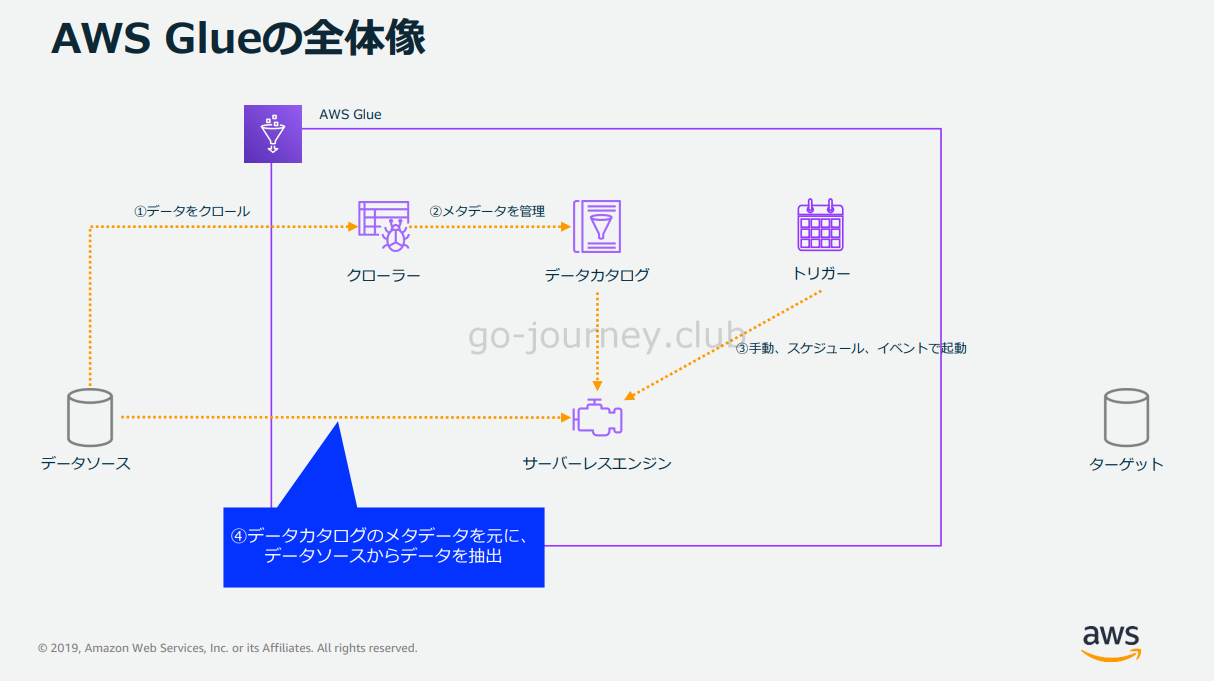
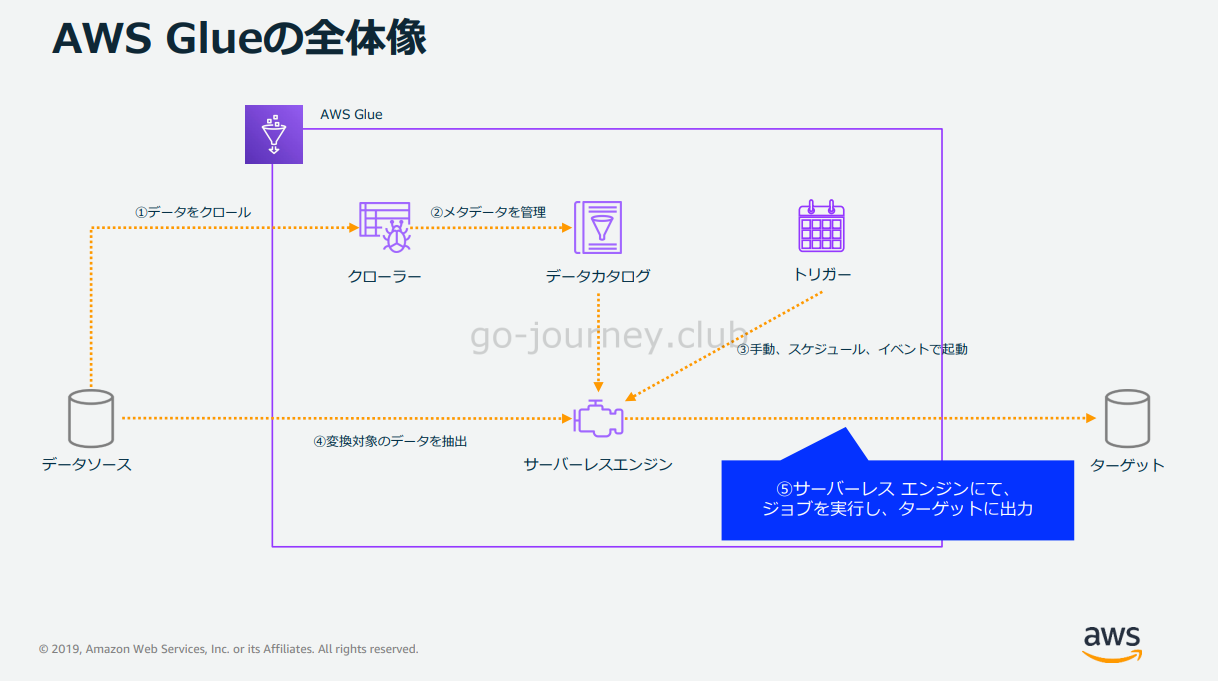
Glue Job の処理の流れ
Glue Job の処理の流れです。
ジョブは AWS 管理画面から実行することも出来ますが、下図のようにトリガーにてジョブの実行タイミングを設定することも出来ます。
ジョブはデータカタログのメタデータを元にデータソースからデータを抽出します。
ジョブはサーバーレスエンジンにて実行されます。
ETL 処理を実行しターゲットに出力します。
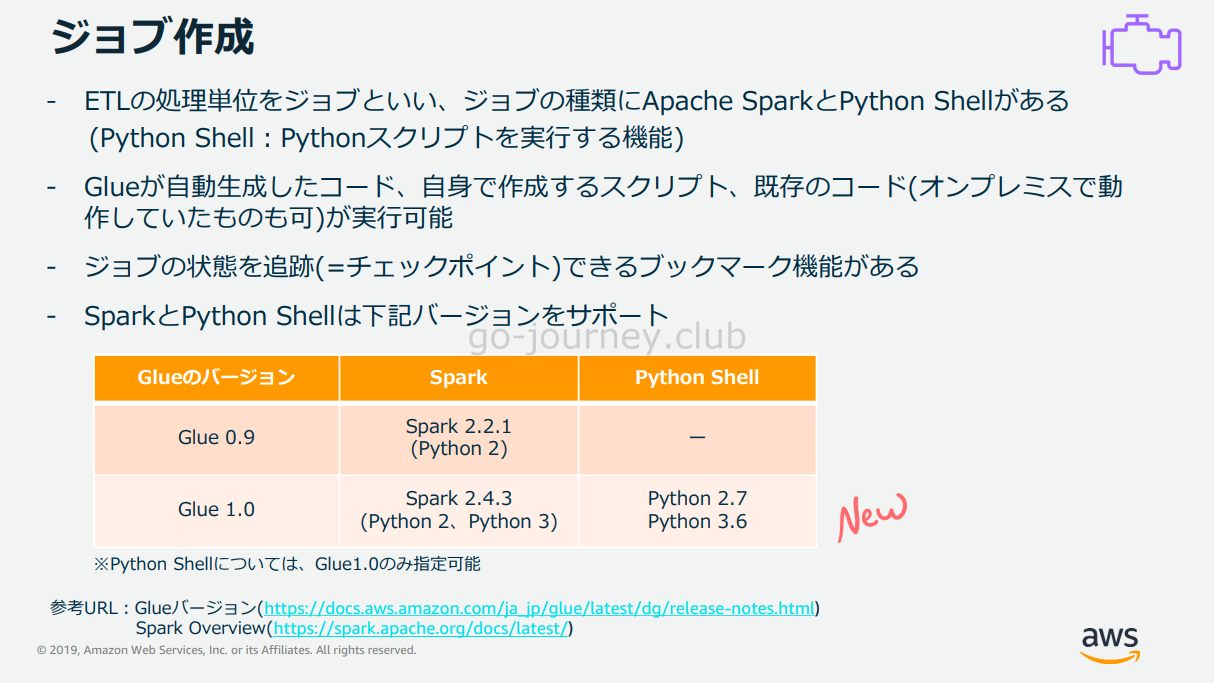
Glue Job とは
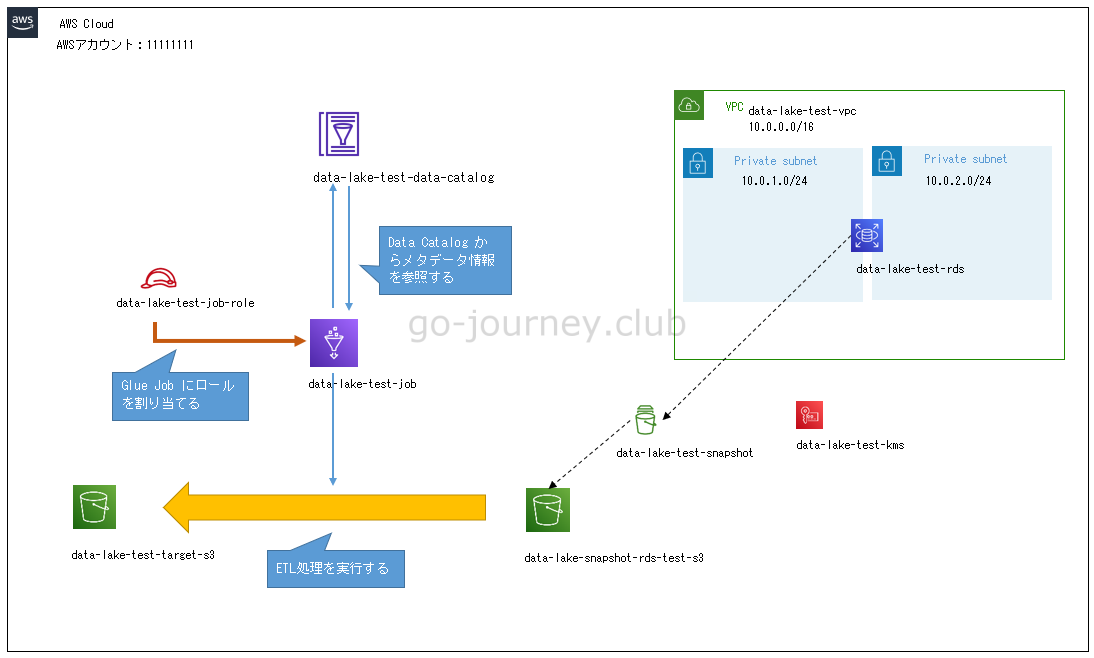
Glue Job の構成図と設計
以下が構成図です。
Glue Job(data-lake-test-job)に IAM ロール(data-lake-test-job-role)を割り当てます。
設計
以下のように設計します。
- Glue Job(data-lake-test-job)を作成する。
- Glue Job(data-lake-test-job)は Glue Data Catalog(data-lake-test-data-catalog)のメタデータを参照する。
- Glue Job(data-lake-test-job)に IAM ロール(data-lake-test-job-role)を割り当てる。
- データソースは data-lake-snapshot-rds-test-s3 で、ターゲットは S3バケット(data-lake-test-target-s3)にする。
IAMロール、IAMポリシーの作成
具体的に IAM ロール、IAM ポリシーを作成します。
■信頼ポリシー
|
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Effect”: “Allow”,
“Principal”: {
“Service”: “glue.amazonaws.com”
},
“Action”: “sts:AssumeRole”
}
]
}
|
■AWSGlueServiceRole(マネジメントポリシー)
|
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Effect”: “Allow”,
“Action”: [
“glue:*”,
“s3:GetBucketLocation”,
“s3:ListBucket”,
“s3:ListAllMyBuckets”,
“s3:GetBucketAcl”,
“ec2:DescribeVpcEndpoints”,
“ec2:DescribeRouteTables”,
“ec2:CreateNetworkInterface”,
“ec2:DeleteNetworkInterface”,
“ec2:DescribeNetworkInterfaces”,
“ec2:DescribeSecurityGroups”,
“ec2:DescribeSubnets”,
“ec2:DescribeVpcAttribute”,
“iam:ListRolePolicies”,
“iam:GetRole”,
“iam:GetRolePolicy”,
“cloudwatch:PutMetricData”
],
“Resource”: [
“*”
]
},
{
“Effect”: “Allow”,
“Action”: [
“s3:CreateBucket”
],
“Resource”: [
“arn:aws:s3:::aws-glue-*”
]
},
{
“Effect”: “Allow”,
“Action”: [
“s3:GetObject”,
“s3:PutObject”,
“s3:DeleteObject”
],
“Resource”: [
“arn:aws:s3:::aws-glue-*/*”,
“arn:aws:s3:::*/*aws-glue-*/*”
]
},
{
“Effect”: “Allow”,
“Action”: [
“s3:GetObject”
],
“Resource”: [
“arn:aws:s3:::crawler-public*”,
“arn:aws:s3:::aws-glue-*”
]
},
{
“Effect”: “Allow”,
“Action”: [
“logs:CreateLogGroup”,
“logs:CreateLogStream”,
“logs:PutLogEvents”
],
“Resource”: [
“arn:aws:logs:*:*:/aws-glue/*”
]
},
{
“Effect”: “Allow”,
“Action”: [
“ec2:CreateTags”,
“ec2:DeleteTags”
],
“Condition”: {
“ForAllValues:StringEquals”: {
“aws:TagKeys”: [
“aws-glue-service-resource”
]
}
},
“Resource”: [
“arn:aws:ec2:*:*:network-interface/*”,
“arn:aws:ec2:*:*:security-group/*”,
“arn:aws:ec2:*:*:instance/*”
]
}
]
}
|
■data-lake-test-job-role-s3-policy
|
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Effect”: “Allow”,
“Action”: [
“s3:GetObject”,
“s3:PutObject”,
“s3:List*”
],
“Resource”: [
“arn:aws:s3:::data-lake-snapshot-rds-test-s3/*”,
“arn:aws:s3::data-lake-test-target-s3/*”
]
}
]
}
|
ジョブはデータソースとターゲット両方の S3 バケットにアクセスします。
■data-lake-test-job-role-kms-policy
|
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Effect”: “Allow”,
“Action”: [
“kms:Decrypt”
],
“Resource”: [
“arn:aws:kms:ap-northeast-1:111111111111:key/xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxx”
]
}
]
}
|
もし RDS のスナップショットが KMS キーで暗号化されている場合は、複合する為に “kms:Decrypt” の権限が必要になります。



コメント